SAP HANA Vector Embeddings leicht gemacht

Vector Datenbanken sind essenziell für RAG (Retrieval Augmented Generation) Prozesse in AI Tools. Neben SAP Document Grounding können Sie auch native SAP HANA Cloud Vector Engine nutzen. Dieser Ansatz erlaubt Ihnen mehr Flexibilität. In diesem Beitrag führe ich Sie Schritt für Schritt durch die Extraktion von PDF Inhalten, Verbindung zu der Datenbank, Embeddings und Retrieval.
Operatives Reporting und strategische Planung in gewohnter Excel Umgebung. Mit der zweiten Auflage meines Praxishandbuchs lernen Sie, SAP Analysis for Microsoft Office einzurichten, aktuelle Daten aus SAP Systemen in Excel auszuwerten und professionelle Berichte zu erstellen.
Setup
Zuerst installieren wir die benötigten Module. In diesem Beispiel verwende ich einfachheitshalber Langchain, Langchain HANA und OpenAI. Für die Kommunikation mit der HANA Cloud Datenbank wird SAP HANA Python Client hdbcli verwendet. Für die Arbeit mit PDF Dateien nutze ich pypdf. Für die Verwaltung von Umgebungsvariablen nutze ich python-dotenv.
pip install hdbcli
pip install pypdf
pip install langchain
pip install langchain-hana
pip install python-dotenvIm nächsten Schritt werden diese importiert
import os
from dotenv import load_dotenv
from hdbcli import dbapi
from pypdf import PdfReader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_hana import HanaDB
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from datetime import datetimeDie API Schlüssel und die Konstanten für den Datenbankzugriff werden in der .env Datei im folgenden Format abgelegt. Dabei werden keine Leerzeichen oder Klammern genutzt. Im Beitrag Wie Sie einen SAP Datasphere Datenbankbenutzer anlegen habe ich detailliert die Einrichtung eines Bentuzers für die HANA Cloud Datenbank von Datasphere beschrieben. Sie können auch eine dedizierte HANA Cloud Datenbank auf BTP nutzen, um die Last auf Datasphere zu verringern.
OPENAI_API_KEY=your_api_key
dbUser=space#user
dbPassword=your_db_user_password
dbHost=your_host
dbPort=your_port_eg_444
dbTable=name_of_the_tableDiese Informationen werden nun in die Umgebungsvariablen geladen, um später auf diese zugreifen zu können.
load_dotenv(override=True)Dokumente laden und aufteilen
Nun laden wir die Dokumente, die wir in der Vector Engine ablegen wollen.
file_path = "C:/temp/Apple_10k_2025.pdf"
pdf =PdfReader(file_path)Anschließend extrahieren wir den Text aus der PDF Datei.
text = ""
for page in pdf.pages:
text += page.extract_text()Dieser wird in mehrere Teile gesplittet.
text_splitter = RecursiveCharacterTextSplitter()
chunks = text_splitter.split_text(text)len(chunks)
print(chunks[0])Metadaten vorbereiten
Neben den Inhalten selbst sind auch Metadaten für das Housekeeping entscheidend. Daher extrahieren wir Metadaten aus dem Dokument.
# Get the current date in YYYYMMDD format
currentdate = datetime.now().strftime('%Y%m%d')
# Extract file name
pdf_file = file_path.split('/')[-1]
# Extract company name. Assuming it comes before the first underscore
# Extract characters before the first underscore in file name
pdf_company = pdf_file.split('_')[0]
# Extract pdf metadata
pdf_author = pdf.metadata.author
pdf_creation_year = pdf.metadata.creation_date.year
pdf_creation_month = pdf.metadata.creation_date.month
pdf_creation_day = pdf.metadata.creation_date.day
pdf_creator = pdf.metadata.creator
pdf_title = pdf.metadata.title
# Central embedding (vs user embedding), therefore good quality
quality = "good"print(pdf_file)
print(pdf_company)Die Metadaten werden für den jeweiligen Teil des Dokumentes erstellt.
##Provide metadata for each chunk
metadatas = [{'embedd_time': currentdate,
'file': pdf_file,
'company': pdf_company,
'author': pdf_author,
'creation_year': pdf_creation_year,
'creation_month': pdf_creation_month,
'creation_day': pdf_creation_day,
'creator': pdf_creator,
'title': pdf_title,
'quality': quality}
for chunk in chunks]Embedding Modell erstellen
Nun instanzieren wir das Modell, welches wir für Embeddings nutzen wollen. In meinem Beispiel verwende ich das OpenAI Modell.
#text-embedding-3-small can have up to 1536 dimensions
#text-embedding-3-large can have up to 3072 dimensions
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")SAP HANA Cloud Datenbank
Um die Embeddings zu speichern, nutzen wir die Vector Engine der SAP HANA Cloud Datenbank. Zunächst stellen wir eine Verbindung zur Datenbank her. Achten Sie darauf, dass Ihre IP in der Whitelist der Datenbank gepflegt ist.
connection = dbapi.connect(
address=os.getenv('dbHost'),
port=os.getenv('dbPort'),
user=os.getenv('dbUser'),
password=os.getenv('dbPassword'),
encrypt=True,
sslValidateCertificate=False
)
print(f"Connected to Datasphere:: {connection.isconnected()}")Nun geben wir die Tabelle an, die für den Zugriff auf die Vektoreinbettungen verwendet werden soll. Die angegebene Tabelle wird automatisch erstellt, falls sie nicht existiert. Falls die angegebene Tabelle bereits existiert, wird sie verwendet. In unserem Beispiel haben wir den Namen der Tabelle in der Umgebungsvariable abgelegt.
db = HanaDB(embedding=embeddings, connection=connection, table_name=os.getenv('dbTable'))Im SAP HANA Database Explorer sehen Sie nun die neu angelegte Tabelle.

Die Tabelle ist zunächst leer. Mit dem folgenden Befehl fügen wir die Dokumentteile samt Metadaten hinzu.
#Add the loaded document chunks
db.add_texts(chunks, metadatas)Jetzt können Sie die jeweiligen Dokumentschnipsel samt Metadaten und dem entsprechenden Vector in der Tabelle sehen.

Ein Vektorindex kann Top-k-Nearest-Neighbor-Abfragen für Vektoren erheblich beschleunigen. Mit der Funktion create_hnsw_index können Sie einen Hierarchical Navigable Small World (HNSW) Vektorindex erstellen.
db.create_hnsw_index()Das Ergebnis ist im Reiter Indexes einsehbar.
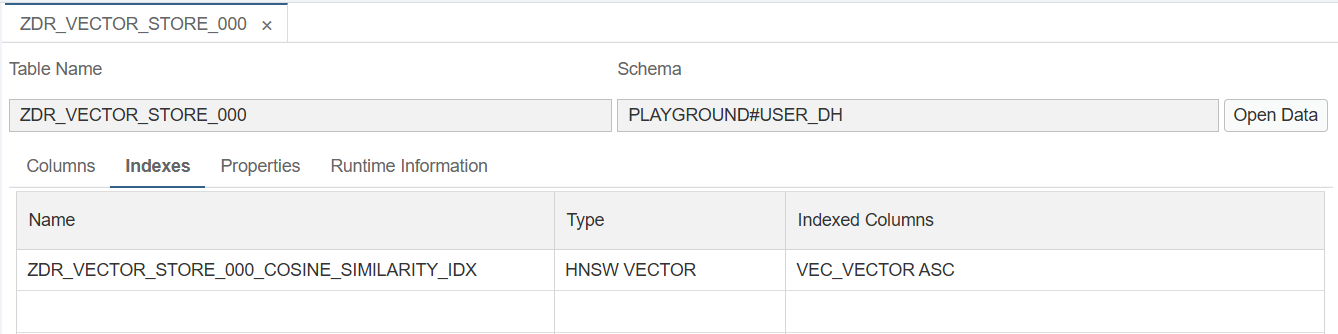
Inhalte abfragen
Nun kann die Datenbank in Ihrer RAG Pipeline genutzt werden. Anbei ein Beispiel für die Ähnlichkeitssuche, wobei die 5 besten Ergebnisse verwenden werden.
query = "Which new products were announced by Apple in 2025? Display the results per quarter."
docs = db.similarity_search(query, k=5)Mit dem folgenden Befehl können die Ergebnisse ausgegeben werden:
#Output
for doc in docs:
print("-" * 80)
print(doc.page_content)
print("-" * 80)Sie können auch bestimmte Metadaten bei der Suche verwenden. Einen Überblick über mögliche Filter finden Sie in der Langchain SAP HANA Cloud Vector Engine Dokumentation.
query = "Which new products were announced in first quarter of 2025?"
docs = db.similarity_search(query, k=2, filter={"quality": "good"})Langchain Dokumente für Embeddings nutzen
Neben dem demonstrierten Beispiel für PDF Dateien. Können Sie auch Langchain Document Objekte für Embeddings nutzen. Diese speichern den Inhalten und die zugehörigen Metadaten. Zum Beispiel:
docs = [
Document(
page_content="Product, Service and Software Announcements. Reis Corp announces new product, service and software offerings at various times during the year. Significant announcements during fiscal year 2025 included the following: First Quarter 2025: • myLaptop Noob 16-in.; Second Quarter 2025: • myLaptop Water 13-innch and• Reis Intelligence™, a artificial intelligence system that leverages SAP HANA Cloud Vector Engine. As well as myPhone 110, myPhone 110 Plus and myPhone 110 Noob.",
metadata={"doc_name": "Reis_10k.txt", "quality": "good"},
),
Document(
page_content="foo",
metadata={"doc_name": "foo.txt", "quality": "good"},
),
Document(
page_content="foo",
metadata={"doc_name": "bar.txt", "quality": "bad"},
),
]
db.add_documents(docs)Inhalte löschen
Wie bereits erwähnt, helfen die Metadaten beim Housekeeping. So können Sie diese zum selektiven Löschen nutzen.
db.delete(filter={"quality": "bad"})Alternativ können Sie einfach alle Embeddings löschen:
## Delete already existing documents from the table
db.delete(filter={})Verbindung zur Datenbank trennen
Denken Sie bitte daran, Ihre Verbindung zur Datenbank anschließend zu trennen.
## Close connection to Datasphere
connection.close()
print(f"\nConnected to Datasphere:: {connection.isconnected()}")Ihre User beklagen sich über langsame Berichte?
- In meinem Newsletter lernen Sie, wie Sie Abhilfe schaffen.
- Entdecken Sie die Möglichkeiten der Performanceoptimierung.
- Praktische Anleitungen ermöglichen Ihnen schnelle Erfolge bei der Optimierung von SAP Systemen.
- Viele Tipps und Tricks zu SAP BI Themen.
- Holen Sie die maximale Performance aus Ihrem SAP BI!
- Bei der Anmeldung zu meinem Newsletter erhalten Sie das Buch „High Performance SAP BI“ als Willkommensgeschenk.








Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!