Python Pandas und NumPy in SAP Datasphere Datenflüssen nutzen

SAP Datasphere ermöglicht es Ihnen, Daten mithilfe von Python Skript zu transformieren. Dabei können Sie Pandas und NumPy Bibliotheken nutzen, die eine Menge an vordefinierten Funktionen liefern. So müssen Sie das Rad nicht jedes Mal neu erfinden. In diesem Beitrag zeige ich Ihnen, wie es geht.
So erleichtern Sie die Entscheidungsfindung und gewinnen einen umfassenden Überblick über Ihr Geschäft! Mit meinem Buch lernen Sie, SAP BPC für die Unternehmensplanung einzurichten, zu nutzen und zu erweitern.
Am besten lässt es sich anhand eines Beispiels erklären. Uns liegen in der Quelle folgende Daten vor. Dabei ist das Datum als String formatiert.
DATE;PRICE;QUANTITY
2021.05.10;1;21
2022.10.11;2;22
2023.07.12;3;23

Das Ziel ist es, basierend auf dem Preis und der Menge die Umsatz auszurechnen, das Datum in das Datentyp Date umzuwandeln, das Jahr, Monat sowie den Tag separat abzulegen und eine konstante Version hinzuzufügen. Die Zieltabelle sieht wie folgt aus.

Mithilfe von Python und Pandas lassen sich all diese Transformationsschritte einfach bewerkstelligen. So könnten wir zum Beispiel den String bei Punkten splitten und den ersten Teil auslesen, um das Jahr aus dem Datum abzuleiten.
data['YEAR2'] = data['DATE'].str.split('.').str.get(0)Wir könnten auch Substring auslesen.
data['YEAR3'] = data['DATE'].str.slice(start=0, stop=4)Während es beim Jahr einwandfrei funktioniert, stößt diese Herangehensweise bei Monaten und Tagen auf ihre Grenzen. So würde uns 2021.05.10 als Monat 05 ausgeben. Wobei 5 das erwartete Ergebnis wäre.
Zum Glück bietet Pandas Konvertierungsfunktionen wie to_datetime an die wir nutzen können. Diese können wir auch in SAP Datasphere nutzen. Leider bietet SAP Datasphere zurzeit noch keine Möglichkeit die Python Syntax zu überprüfen oder den Code zu debuggen. Daher bietet es sich an, die Logik zunächst lokal zu prüfen. Dazu können Sie zum Beispiel Visual Studio Code oder Jupyter Notebook verwenden. Die nachfolgenden Beispiele wurden in Jupyter erstellt.
Während in Datasphere die Pandas Bibliothek schon standardmäßig importiert wurde und die Daten als DataFrame Datenstruktur definiert wurden, müssen Sie es lokal selbst machen. Anschließend können Sie die Beispieldaten erfassen oder auch aus einer CSV Datei laden.
import pandas as pd
input = {'DATE': ['2021.05.10', '2022.10.11', '2023.07.12' ], 'PRICE': ['1', '2', '3'], 'QUANTITY': ['21', '22', '23']}
#csv import
#input = pd.read_csv('pandas_extract_year.csv', sep=";")
data = pd.DataFrame(input)
print("Input:")
print(data)
Um den Umsatz zu berechnen, fügen wir eine neue Spalte hinzu und multiplizieren den Preis und die Menge.
data['REVENUE'] = pd.to_numeric(data['PRICE']) * pd.to_numeric(data['QUANTITY'])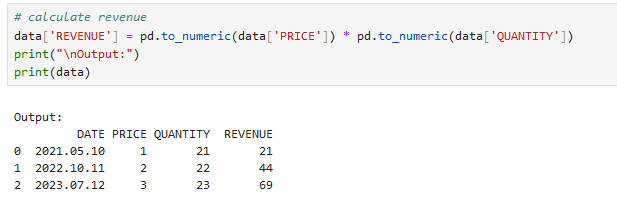
Anschließend konvertieren wir den String als Datum und lesen das Jahr, Monat und den Tag aus. Diese werden in neuen Spalten als String abgelegt.
# convert the Date to datetime
data['FORMATTED_DATE'] = pd.to_datetime(data['DATE'])
# add a column for Year, Month and Date
data['YEAR'] = data['FORMATTED_DATE'].dt.year.astype('string')
data['MONTH'] = data['FORMATTED_DATE'].dt.month.astype('string')
data['DAY'] = data['FORMATTED_DATE'].dt.day.astype('string')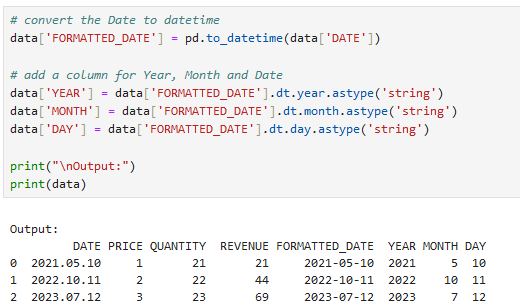
Schließlich fügen wir eine Spalte für Version ein und setzen die Version konstant auf Actual.
# add a column for version with default value
data['VERSION'] = 'Actual'
#oder auch: data = data.assign(VERSION='Actual')
Nachdem wir uns vergewissert haben, dass die Logik die gewünschten Ergebnisse liefert, transferieren wir unseren Code in den Datasphere Datenfluss.
import pandas as pd
input = {'DATE': ['2021.05.10', '2022.10.11', '2023.07.12' ], 'PRICE': ['1', '2', '3'], 'QUANTITY': ['21', '22', '23']}
#csv import
#input = pd.read_csv('pandas_extract_year.csv', sep=";")
data = pd.DataFrame(input)
print("Input:")
print(data)
# in Datasphere ist data schon als DataFrame definiert
# Datasphere Logik ab hier:
# calculate revenue
data['REVENUE'] = pd.to_numeric(data['PRICE']) * pd.to_numeric(data['QUANTITY'])
# convert the Date to datetime
data['FORMATTED_DATE'] = pd.to_datetime(data['DATE'])
# add a column for Year, Month and Date
data['YEAR'] = data['FORMATTED_DATE'].dt.year.astype('string')
data['MONTH'] = data['FORMATTED_DATE'].dt.month.astype('string')
data['DAY'] = data['FORMATTED_DATE'].dt.day.astype('string')
# add a column for version with default value
data['VERSION'] = 'Actual'
#oder auch: data = data.assign(VERSION='Actual')
print("\nOutput:")
print(data)Dazu legen wir einen neuen Datenfluss an und fügen einen Script Operator hinzu.

Im Skript Operator legen wir neue Spalten an, die mit der Zieltabelle übereinstimmen.

Definieren Sie dabei den Datentyp, der auch in der Zieltabelle verwendet wird.
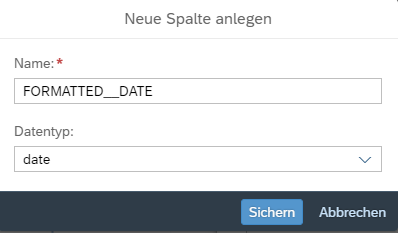
Für unseren Beispiel habe ich folgende Spalten hinzugefügt.
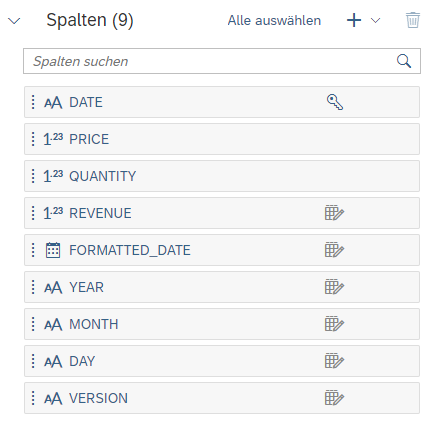
Anschließend fügen wir den zuvor definierten Code unter dem „Provide the function body for data transformation“ Abschnitt ein.
def transform(data):
"""
This function body should contain all the desired transformations on incoming DataFrame. Permitted builtin functions
as well as permitted NumPy and Pandas objects and functions are available inside this function.
Permitted NumPy and Pandas objects and functions can be used with aliases 'np' and 'pd' respectively.
This function executes in a sandbox mode. Please refer the documentation for permitted objects and functions. Using
any restricted functions or objects would cause an internal exception and result in a pipeline failure.
Any code outside this function body will not be executed and inclusion of such code is discouraged.
:param data: Pandas DataFrame
:return: Pandas DataFrame
"""
#####################################################
# Provide the function body for data transformation #
#####################################################
# calculate revenue
data['REVENUE'] = pd.to_numeric(data['PRICE']) * pd.to_numeric(data['QUANTITY'])
# convert the Date to datetime
data['FORMATTED_DATE'] = pd.to_datetime(data['DATE'])
# add a column for Year, Month and Date
data['YEAR'] = data['FORMATTED_DATE'].dt.year.astype('string')
data['MONTH'] = data['FORMATTED_DATE'].dt.month.astype('string')
data['DAY'] = data['FORMATTED_DATE'].dt.day.astype('string')
# add a column for version with default value
data['VERSION'] = 'Actual'
#data = data.assign(VERSION='Actual')
return dataDie erstellten und mithilfe von Python gefüllten Spalten werden nun der Zieltabelle zugeordnet.

Nachdem der Datenfluss aktiviert und ausgeführt wurde erscheinen die transformierten Daten in der Zieltabelle.

Ich hoffe, dass dieser Artikel Ihnen weitergeholfen hat und freue mich über Ihre Kommentare.
Ihre User beklagen sich über langsame Berichte?
- In meinem Newsletter lernen Sie, wie Sie Abhilfe schaffen.
- Entdecken Sie die Möglichkeiten der Performanceoptimierung.
- Praktische Anleitungen ermöglichen Ihnen schnelle Erfolge bei der Optimierung von SAP Systemen.
- Viele Tipps und Tricks zu SAP BI Themen.
- Holen Sie die maximale Performance aus Ihrem SAP BI!
- Bei der Anmeldung zu meinem Newsletter erhalten Sie das Buch „High Performance SAP BI“ als Willkommensgeschenk.









Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!