Vibe Coding mit SAP AI Core

Neuerdings ist SAP AI Core als API im Cline AI Coding Agent verfügbar. Somit können Sie Ihre Entwicklung innerhalb einer gesicherten SAP Umgebung betreiben und sicherstellen, dass vertrauliche Informationen nicht nach außen gelangen. In diesem Beitrag führe ich Sie Schritt für Schritt durch die Einrichtung.
Bringen Sie die Analyse- und Reporting-Funktionen von SAP Analytics Cloud in Ihre gewohnte Microsoft Office-Umgebung! Mit meinem neuen Buch lernen Sie, das SAP Analytics Cloud Add-in in Excel und PowerPoint einzusetzen, Daten in Echtzeit zu analysieren und ansprechende Berichte sowie Präsentationen zu erstellen.
Nachfolgend führe ich Sie durch die einzelnen Einrichtungsschritte:
- Cline in VS Code installieren
- SAP AI Core als API Provider konfigurieren
- Context7 MCP Server konfigurieren
- Perplexity MCP Server konfigurieren
- Eigene MCP Server hinzufügen
- MCP Inspector nutzen
- Cline Rules definieren
- .clineignore einrichten
- Memory Bank einrichten
- Workflows nutzen
Cline in VS Code installieren
Laden Sie zunächst Visual Studio Code herunter und installieren Sie das Programm. In VS Code, wählen Sie Extensions aus, suchen Sie nach Cline und installieren Sie die Erweiterung.

SAP AI Core als API Provider konfigurieren
Wählen Sie nun in Cline SAP AI Core als API Provider aus. Die Konfiguration von SAP AI Core habe ich im Beitrag Wie Sie SAP BTP AI Core nutzen ausführlich beschrieben. Übertragen Sie Sie die Einträge aus dem AI Core Schlüssel in die Cline Einstellungen, wie auf dem folgenden Bild dargestellt.

Wählen Sie dabei Orchestration Mode aus, um Zugriff auf alle verfügbaren Modelle zu erhalten und eine harmonisierte API zu nutzen. Alternativ können Sie einzelne Modelle bereitstellen und mithilfe der nativen APIs auf diese zugreifen. Wählen Sie das gewünschte Modell aus und schließen Sie die Konfiguration mit Done ab.
Context7 MCP Server konfigurieren
Um Cline mit der aktuellen Dokumentation für Programmiersprachen und Frameworks zu versorgen, konfigurieren wir context7 als MCP. Zwar bietet Cline über MCP Servers Marketplace eine automatische Konfiguration an. Allerdings funktioniert diese unter Windows mehr schlecht als recht. Daher führe ich Sie durch die manuelle Installation. Auf Ihrem System müssen Node.js und npm sowie Git installiert sein. Als Terminal sollten Sie PowerShell verwenden.
Öffnen Sie PowerShell und navigieren Sie zu dem Cline Ordner, wo die MCP Server gespeichert werden:
cd C:\Users\<Ihr Benutzer>\Documents\Cline\MCPZum Beispiel:
cd C:\Users\denis\Documents\Cline\MCPLöschen Sie die ggf. vorhandenen Ordner mithilfe des folgenden Befehls, um eine saubere Installation zu gewährleisten
Remove-Item -Recurse -Force context7-mcpClonen Sie nun mit git die context7 Repository von github. Wenn Sie kein git verwenden, können Sie auch direkt zu github gehen, das Verzeichnis als zip Datei herunterladen und in dem context7-mcp Ordner zu entpacken. Allerdings ist git für die Versionskontrolle unerlässlich und sollte auf keinem Computer fehlen.
git clone https://github.com/upstash/context7-mcp
Wechseln Sie nun in den context7-mcp Ordner.
cd C:\Users\<YourUsername>\Documents\Cline\MCP\context7-mcpZum Beispiel:
cd C:\Users\denis\Documents\Cline\MCP\context7-mcpInstallieren Sie die Abhängigkeiten mit npm install:
npm install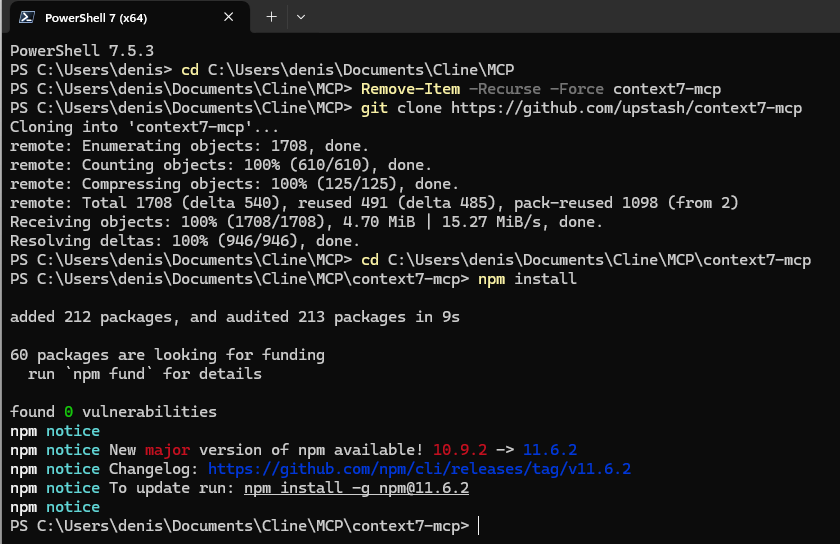
Kompilieren Sie nun das Projekt mit npm run build. Die chmod Fehlermeldung können Sie dabei ignorieren.
npm run build
Wechseln Sie nun zu Cline, wählen Sie das Server Icon aus, klicken Sie auf Configure und anschließend auf Configure MCP Servers.

Fügen Sie anschließend die folgende JSON Konfiguration ein.
{
"mcpServers": {
"context7-mcp": {
"autoApprove": [
"resolve-library-id",
"get-library-docs"
],
"disabled": false,
"timeout": 60,
"command": "node",
"args": [
"C:\\Users\\<enter your user here>\\Documents\\Cline\\MCP\\context7-mcp\\dist\\index.js"
],
"transportType": "stdio"
}
}
}Zum Beispiel:
{
"mcpServers": {
"context7-mcp": {
"autoApprove": [
"resolve-library-id",
"get-library-docs"
],
"disabled": false,
"timeout": 60,
"command": "node",
"args": [
"C:\\Users\\denis\\Documents\\Cline\\MCP\\context7-mcp\\dist\\index.js"
],
"transportType": "stdio"
}
}
}Nun wird der contex7-mcp als grün angezeigt. Sie können den MCP Server über use context7 Befehl aufrufen oder die folgende Regel in Cline hinzufügen:
Always use context7 when I need code generation, setup or configuration steps, or
library/API documentation. This means you should automatically use the Context7 MCP
tools to resolve library id and get library docs without me having to explicitly ask.Perplexity MCP Server konfigurieren
Ein weiterer hilfreicher MCP Server ist Perplexity. Damit kann Cline eine Websuche ausführen. Während Context7 mir einiges an Kopfzerbrechen bereitet hat, funktioniert die Konfiguration von Perplexity einwandfrei. Holen Sie sich einen API Schlüssel und fügen Sie folgendes zur MCP Konfiguration hinzu.
{
"mcpServers": {
"perplexity": {
"command": "npx",
"args": ["-y", "@perplexity-ai/mcp-server"],
"env": {
"PERPLEXITY_API_KEY": "your_key_here"
}
}
}
}Die Konfigurationsdatei in Cline sieht nun wie folgt aus:
{
"mcpServers": {
"context7-mcp": {
"autoApprove": [
"resolve-library-id",
"get-library-docs"
],
"disabled": false,
"timeout": 60,
"command": "node",
"args": [
"C:\\Users\\denis\\Documents\\Cline\\MCP\\context7-mcp\\dist\\index.js"
],
"transportType": "stdio"
},
"perplexity": {
"command": "npx",
"args": [
"-y",
"@perplexity-ai/mcp-server"
],
"env": {
"PERPLEXITY_API_KEY": "pplx-<your-api-key>"
},
"autoApprove": [
"perplexity_search"
]
}
}
}
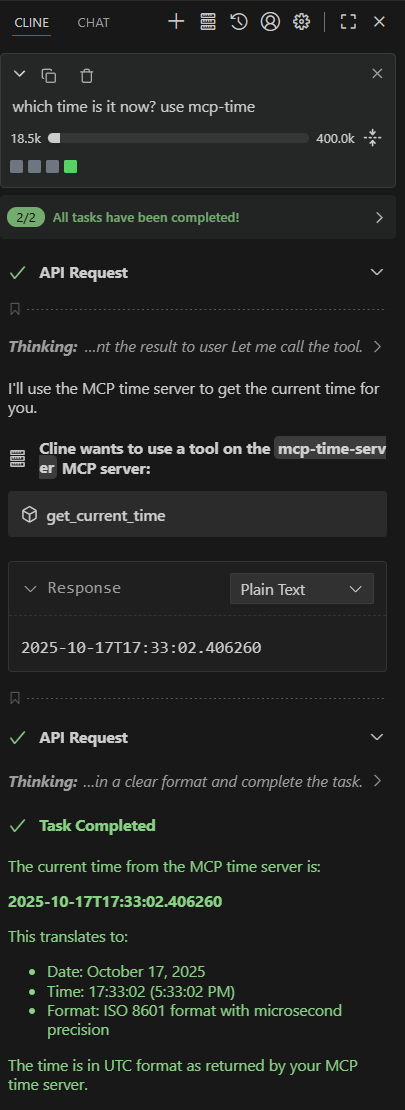
Eigene MCP Server hinzufügen
Selbstverständlich können Sie auch eigene MCP Server einrichten und Clines zur Verfügung stellen. Anbei ein einfaches Beispiel für einen MCP Server, der als Tools die aktuelle Zeit ausgibt. Dabei habe ich zwecks Modularisierung zwei Python Dateien angelegt: server.py und main.py. Die server.py Datei enthält den eigentlichen Code:
# server.py
from mcp.server.fastmcp import FastMCP
from datetime import datetime
# Create an instance of the FastMCP server
mcp = FastMCP()
@mcp.tool()
def get_current_time() -> str:
"""
Use this tool to get the current time in ISO format as a string.
Returns:
str: Current time in ISO format. The full format looks like 'YYYY-MM-DD HH:MM:SS.mmmmmm'. The default separator between date and time is 'T'. e.g 2025-10-17T17:04:22.739427.
"""
return datetime.now().isoformat()Dieser wird über main.py aufgerufen:
from server import mcp
if __name__ == "__main__":
mcp.run(transport="stdio")Nun können wir den MCP Server zu cline_mcp_settings.json hinzufügen:
"mcp-time": {
"autoApprove": [],
"transportType": "stdio",
"command": "uv",
"args": [
"run",
"--directory", "D:\\Users\\denis\\python_projekte\\mcp_server_time\\src",
"main.py"
]
}Oder mit dem direkten Pfad zu uv:
"mcp-time": {
"autoApprove": [],
"transportType": "stdio",
"command": "C:\\Users\\denis\\.local\\bin\\uv.exe",
"args": [
"run",
"--directory", "D:\\Users\\denis\\python_projekte\\mcp_server_time\\src",
"main.py"
]
}Die komplette Konfiguration sieht nun wie folgt aus:
{
"mcpServers": {
"context7-mcp": {
"autoApprove": [
"resolve-library-id",
"get-library-docs"
],
"disabled": false,
"timeout": 60,
"command": "node",
"args": [
"C:\\Users\\denis\\Documents\\Cline\\MCP\\context7-mcp\\dist\\index.js"
],
"transportType": "stdio"
},
"perplexity": {
"command": "npx",
"args": [
"-y",
"@perplexity-ai/mcp-server"
],
"env": {
"PERPLEXITY_API_KEY": "pplx-<insert_api_key_here>"
},
"autoApprove": [
"perplexity_search"
]
},
"mcp-time": {
"autoApprove": [],
"transportType": "stdio",
"command": "uv",
"args": [
"run",
"--directory", "D:\\Users\\denis\\python_projekte\\mcp_server_time\\src",
"main.py"
]
}
}
}Nun steht der Server Cline zur Verfügung.

Cline kann diesen MCP Server bei Bedarf nutzen.
Neben Werkzeugen / Tools können Sie auch MCP Server für Ressourcen bereitstellen. Der folgende MCP Server gibt den Inhalt eines CVs aus.
from mcp.server.fastmcp import FastMCP
from pathlib import Path
# Create an instance of the FastMCP server
mcp = FastMCP()
@mcp.resource(
uri="data://cv",
name="DenisReisCv",
description="Provides the CV of Denis Reis.",
mime_type="text/markdown",
)
def get_cv() -> str:
"""
Retrieves the professional CV of Denis Reis.
Returns:
str: The complete CV content in markdown format, or an error message if unavailable.
Raises:
Returns error message strings rather than exceptions for graceful degradation.
"""
try:
# Get the directory where this script is located
script_dir = Path(__file__).parent
cv_path = script_dir / "denis_reis_cv.md"
with open(cv_path, "r", encoding="utf-8") as cv_file:
cv_content = cv_file.read()
return cv_content
except FileNotFoundError:
return "Error: CV file not found."
except Exception as e:
return f"Error reading CV: {str(e)}"
def main():
# Initialize and run the server
mcp.run(transport='stdio')
if __name__ == "__main__":
main()Mit der Konfiguration fügen wir diesen MCP Server Cline hinzu:
"mcp-cv": {
"autoApprove": [],
"disabled": false,
"timeout": 60,
"type": "stdio",
"command": "uv",
"args": [
"run",
"--directory",
"D:\\Users\\denis\\python_projekte\\mcp_server_resources\\src",
"main.py"
]
}Cline kann nun diese Informationen für seine Antworten nutzen.

MCP Inspector nutzen
Sie können den MCP Inspector nutzen, um Ihre MCP Server zu analysieren.
npx @modelcontextprotocol/inspectorSie können auch direkt einen spezifischen MCP Server starten:
npx @modelcontextprotocol/inspector uv run --directory "D:\\Users\\denis\\python_projekte\\mcp_server_time\\src" main.py
Cline Regeln konfigurieren
Die Cline Rules dienen dazu, Cline Anweisungen zu geben. Sie sind im Grunde eine permanente Möglichkeit, Kontext und Präferenzen für Ihre Projekte oder alle Ihre Unterhaltungen zu speichern.
Um eine neue Regel anzulegen, klicken Sie auf Manage Cline Rules & Workflows.
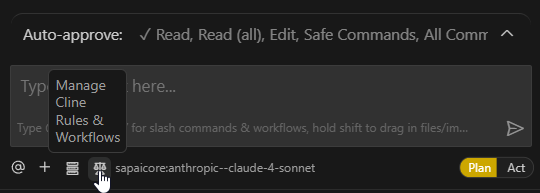
Hier können Sie nun globale Regeln, die für alle Projekte gelten, oder Workspace Regeln, die nur für das aktuelle Projekt gelten, anlegen.

Unter Awesome Cursor Rules sowie Cline Prompts finden Sie eine Sammlung von Regeln für verschiedene Programmiersprachen. Anbei meine Regeln für Python:
# Cline AI Coding Agent Rules for Python Development
## Core Principles
- **Simplicity First**: Always prefer simple solutions over complex ones
- **Brevity**: Minimize lines of code while maintaining readability
- **Iteration Over Creation**: Look for existing code to extend before creating new implementations
- **Pattern Consistency**: Preserve existing patterns unless explicitly instructed otherwise
## Code Quality & Organization
### Duplication & Reuse
- **Check Before Writing**: Search the codebase for similar functionality before implementing
- **DRY Principle**: Avoid code duplication by extracting common logic into reusable functions/classes
- **Consolidate Changes**: When replacing implementations, remove old code to prevent duplicate logic
### File Organization
- **Size Limits**: Keep files under 200-300 lines; refactor when approaching this threshold
- **Modular Structure**: Break large files into logical modules with clear responsibilities
- **No Disposable Scripts**: Avoid one-off scripts in project files; use temporary scripts in auxiliary folder instead
### Code Hygiene
- **Preserve Documentation**: Never delete existing comments or docstrings
- **Clean Codebase**: Maintain organization and remove unused imports/variables
- **Meaningful Names**: Use descriptive variable and function names that reflect purpose
## Change Management
### Scope Control
- **Targeted Changes**: Focus only on code relevant to the current task
- **No Scope Creep**: Don't touch unrelated code or introduce unrelated improvements
- **Minimal Modifications**: Only make changes you're confident are necessary and well-understood
### Impact Assessment
- **Ripple Effect Analysis**: Consider what other methods/areas might be affected by changes
- **Dependency Awareness**: Check for callers and dependencies before modifying function signatures
- **Test Implications**: Consider how changes affect existing tests
### Pattern Preservation
- **Respect Working Solutions**: Don't refactor features that work well unless explicitly requested
- **Exhaust Existing Patterns**: Try all options within current implementation before introducing new patterns
- **Incremental Evolution**: Make small, iterative improvements rather than wholesale rewrites
## Environment
### Environment Safety
- **`.env` Protection**: Never overwrite `.env` files without explicit confirmation
- **Secrets Handling**: Never commit or log sensitive data
## Workflow Best Practices
### Before Making Changes
1. Understand the existing implementation
2. Search for similar code that could be reused
3. Identify potential side effects
4. Plan minimal changes needed
### During Implementation
1. Follow established patterns in the codebase
2. Write clean, self-documenting code
3. Keep changes atomic and focused
4. Consider backward compatibility
### After Changes
1. Remove obsolete code if new pattern replaces old
2. Update relevant comments/documentation
3. Verify no unintended side effects
4. Check file size and refactor if needed
## Python-Specific Guidelines
### Code Style
- Follow PEP 8 conventions
- Use type hints where they add clarity
- Prefer list/dict comprehensions for simple transformations
- Use context managers (`with` statements) for resource management
### Import Organization
- Group imports: standard library → third-party → local
- Remove unused imports
- Avoid wildcard imports (`from x import *`)
### Error Handling
- Use specific exception types
- Don't silence exceptions without good reason
- Provide meaningful error messages
## Priority Order
When rules conflict, follow this priority:
1. **Safety**: Don't break existing functionality or compromise data/security
2. **Scope**: Stay focused on the task at hand
3. **Simplicity**: Choose the simpler solution
4. **Consistency**: Follow existing patterns
5. **Quality**: Maintain clean, organized code.clineignore einrichten
Nun weiß Cline, wie es etwas machen muss. Genauso wichtig ist es zu wissen, was es nicht machen soll. Die .clineignore Datei dient als Konfigurationsdatei auf Projektebene und weist Cline an, bestimmte Dateien und Verzeichnisse bei der Analyse Ihrer Codebasis zu ignorieren. Ähnlich wie die bekannte .gitignore verwendet auch die .clineignore Musterabgleich, um festzulegen, welche Dateien aus dem Kontext und den Operationen von Cline ausgeschlossen werden sollen. So wird das Rauschen reduziert, indem automatisch generierte Dateien, Build-Artefakte und andere unwesentliche Inhalte ausgeschlossen werden. Gleichzeitig wird die Leistung verbessert, da die Menge des von Cline zu verarbeitenden Codes begrenzt wird. Dadurch können Sie Clines Aufmerksamkeit gezielt auf die relevanten Teile Ihrer Codebasis lenken. Nicht zuletzt trägt die .clineignore auch zum Schutz sensibler Daten bei, indem sie verhindert, dass Cline auf vertrauliche Konfigurationsdateien zugreift.
# Dependencies
node_modules/
**/node_modules/
.pnp
.pnp.js
# Build outputs
/build/
/dist/
/.next/
/out/
# Testing
/coverage/
# Environment variables
.env
.env.local
.env.development.local
.env.test.local
.env.production.local
# Large data files
*.csv
*.xlsxMemory Bank einrichten
Die Memory Bank ist ein strukturiertes Dokumentationssystem, das es Cline ermöglicht, den Kontext über mehrere Sitzungen hinweg aufrechtzuerhalten. Dadurch wandelt sich Cline von einem zustandslosen Assistenten in einen dauerhaften Entwicklungspartner, der sich die Details Ihres Projekts über längere Zeiträume hinweg effektiv merken kann.
Kopieren Sie den folgenden Text als eine neue Regel in Cline:
# Cline's Memory Bank
I am Cline, an expert software engineer with a unique characteristic: my memory resets completely between sessions. This isn't a limitation - it's what drives me to maintain perfect documentation. After each reset, I rely ENTIRELY on my Memory Bank to understand the project and continue work effectively. I MUST read ALL memory bank files at the start of EVERY task - this is not optional.
## Memory Bank Structure
The Memory Bank consists of core files and optional context files, all in Markdown format. Files build upon each other in a clear hierarchy:
flowchart TD
PB[projectbrief.md] --> PC[productContext.md]
PB --> SP[systemPatterns.md]
PB --> TC[techContext.md]
PC --> AC[activeContext.md]
SP --> AC
TC --> AC
AC --> P[progress.md]
### Core Files (Required)
1. `projectbrief.md`
- Foundation document that shapes all other files
- Created at project start if it doesn't exist
- Defines core requirements and goals
- Source of truth for project scope
2. `productContext.md`
- Why this project exists
- Problems it solves
- How it should work
- User experience goals
3. `activeContext.md`
- Current work focus
- Recent changes
- Next steps
- Active decisions and considerations
- Important patterns and preferences
- Learnings and project insights
4. `systemPatterns.md`
- System architecture
- Key technical decisions
- Design patterns in use
- Component relationships
- Critical implementation paths
5. `techContext.md`
- Technologies used
- Development setup
- Technical constraints
- Dependencies
- Tool usage patterns
6. `progress.md`
- What works
- What's left to build
- Current status
- Known issues
- Evolution of project decisions
### Additional Context
Create additional files/folders within memory-bank/ when they help organize:
- Complex feature documentation
- Integration specifications
- API documentation
- Testing strategies
- Deployment procedures
## Core Workflows
### Plan Mode
flowchart TD
Start[Start] --> ReadFiles[Read Memory Bank]
ReadFiles --> CheckFiles{Files Complete?}
CheckFiles -->|No| Plan[Create Plan]
Plan --> Document[Document in Chat]
CheckFiles -->|Yes| Verify[Verify Context]
Verify --> Strategy[Develop Strategy]
Strategy --> Present[Present Approach]
### Act Mode
flowchart TD
Start[Start] --> Context[Check Memory Bank]
Context --> Update[Update Documentation]
Update --> Execute[Execute Task]
Execute --> Document[Document Changes]
## Documentation Updates
Memory Bank updates occur when:
1. Discovering new project patterns
2. After implementing significant changes
3. When user requests with **update memory bank** (MUST review ALL files)
4. When context needs clarification
flowchart TD
Start[Update Process]
subgraph Process
P1[Review ALL Files]
P2[Document Current State]
P3[Clarify Next Steps]
P4[Document Insights & Patterns]
P1 --> P2 --> P3 --> P4
end
Start --> Process
Note: When triggered by **update memory bank**, I MUST review every memory bank file, even if some don't require updates. Focus particularly on activeContext.md and progress.md as they track current state.
REMEMBER: After every memory reset, I begin completely fresh. The Memory Bank is my only link to previous work. It must be maintained with precision and clarity, as my effectiveness depends entirely on its accuracy.
Initialisieren Sie anschließend die Memory Bank mit dem folgenden Befehl:
initialize memory bankAnschließend können Sie mit der Implementierung starten und während des Projektes folgende Befehle nutzen.
update memory bankMemory Bank aktualisieren – Lösen Sie diesen Befehl während einer laufenden Aufgabe aus, um eine vollständige Überprüfung und Aktualisierung der gesamten Projektdokumentation zu starten. Dies ist nützlich, wenn sich größere Änderungen im Code ergeben haben, die Cline in seinem Kontext speichern soll.
follow your custom instructions„Folge deinen benutzerdefinierten Anweisungen“ – verwenden Sie diesen Befehl zu Beginn von Aufgaben, um Cline anzuweisen, die vorhandenen Memory Bank-Dateien zu lesen und dort weiterzumachen, wo Sie in der vorherigen Sitzung aufgehört haben. Dies stellt sicher, dass Cline den aktuellen Projektkontext sofort versteht.
Workflows nutzen
Für sich wiederholende Abläufe können sie auch Workflows nutzen, z.B. Self Improving Cline. Um einen Workflow zu definieren, wählen Sie Manage Cline Rules & Workflows und selektieren Sie anschließend Workflows Reiter.

Workflows können mit /workflow-name Befehl aufgerufen werden. Zum Beispiel
/self-improving-cline.mdIhre User beklagen sich über langsame Berichte?
- In meinem Newsletter lernen Sie, wie Sie Abhilfe schaffen.
- Entdecken Sie die Möglichkeiten der Performanceoptimierung.
- Praktische Anleitungen ermöglichen Ihnen schnelle Erfolge bei der Optimierung von SAP Systemen.
- Viele Tipps und Tricks zu SAP BI Themen.
- Holen Sie die maximale Performance aus Ihrem SAP BI!
- Bei der Anmeldung zu meinem Newsletter erhalten Sie das Buch „High Performance SAP BI“ als Willkommensgeschenk.









Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!