How-To SAP BI – InfoCube Modellierung

Die optimale Modellierung von InfoCubes hängt von vielen Aspekten ab. Dementsprechend breit ist dieser Beitrag aufgestellt. Zunächst stelle ich das ER-Modell und das Stern-Schema vor. Nach diesen Grundlagen stelle ich die Modellierungsregeln im Hinblick auf die Performance vor.
ER-Modell
ER steht für Entity-Relationship-Modell, oft auch Objekt-Beziehungsmodell genannt. Mit diesem Modell wird bei der Datenmodellierung beschrieben in welcher Beziehung verschiedene Datenobjekte zueinander stehen. Die Bestandteile eines ER-Modells sind Entitäten (bzw. Objekte), Attribute und Beziehungen.
- Entität – Entitäten sind Objekte aus der realen Welt, die eindeutig identifiziert werden können. Zum Beispiel Mitarbeiter, Kunde, Auftrag, Projekt. Sie werden als Rechtecke dargestellt.
- Attribut – Attribute oder Merkmale stellen Eigenschaften von Entitäten dar. Sie werden als Ovale dargestellt und die Schlüsselmerkmale werden hervorgehoben.
- Beziehung – Beziehungen werden als Rauten dargestellt, deren Enden mit den Rechtecken (Entitäten) verbunden werden.
Das ER-Modell ist besonders hilfreich, um Quelldaten sehr verständlich zu beschreiben. Vor allem die Beziehungen spielen bei der Modellierung von InfoCubes eine wichtige Rolle.
Betrachten wir das folgende Beispiel.

ER-Modell 1:n
Ein Angestellter hat einen Namen und eine Personalnummer. (Mehrere Angestellte können einen und denselben Namen tragen, aber die Personalnummer ist immer eindeutig.) Dieser Angestellte kann mehr als nur ein Projekt leiten. Ein Projekt hat jedoch immer nur einen Projektleiter (dieser muss für alles den Kopf hinhalten).
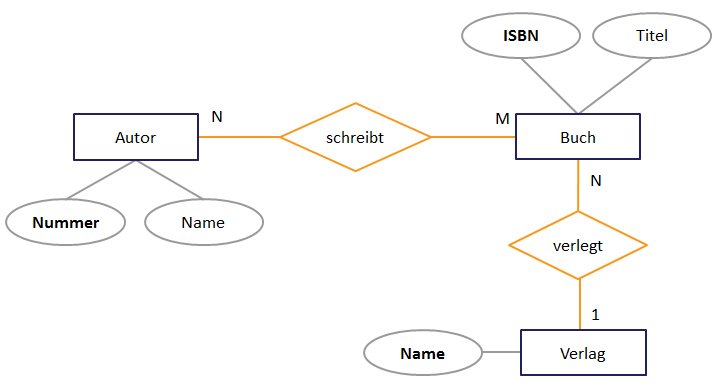
ER-Modell n:m
In diesem Beispiel schreibt ein Autor ein Buch, welches von einem Verlag verlegt wird. Ein Autor kann mehrere Bücher schreiben. Und ein Buch kann auch von mehr als nur einem (Co-)Autor geschrieben werden. Ein Buch wird aber immer von nur einem Verlag verlegt. Ein Verlag wiederrum gibt mehrere Bücher aus.
Stern-Schema
Das Stern-Schema (Star-Schema) wurde entwickelt, um ein Datenmodell für analytische Anwendungen zu schaffen, das einfach in relationalen Datenbanken, also im Relationen-Schema umgesetzt werden kann. Es ist das grundsätzliche Datenmodell für fast alle analytischen Systeme, die mit relationalen Datenbanken umgesetzt werden. Somit ist es auch das Basismodell für InfoCubes im BW.
Dabei werden die Kennzahlen in einer zentralen Faktentabelle gespeichert. Merkmale werden nicht direkt als Schlüssel gespeichert sondern als separat generierte Dimensionsschlüssel. Diese sind wiederrum Schlüssel der Dimensionstabellen, die alle Merkmale einer Dimension enthalten. In der folgenden Abbildung ist ein Stern-Schema anhand eines einfachen Modells, das Kunde, Produkt und Zeit enthält, dargestellt.

SAP BI Sternschema
Ein Vorteil des Stern-Schemas ist, dass als generierte Dimensionsschlüssel sehr kurze Schlüssel (etwa 4-Byte Integer) verwendet werden, und nicht eventuell sehr lange sprechende Merkmalsschlüssel. Dies bringt Vorteile im Hinblick auf die Performance.
Das BW verwendet eine erweiterte Form des Stern-Schemas. Die Erweiterung besteht darin, dass die Dimensionstabellen nicht die Stammdateninformationen enthalten. Die Stammdaten werden in zusätzlichen, separaten Tabellen abgelegt („denormaliserte“ Stammdaten). Man kann sagen, dass das Stern-Schema um die Stammdatentabellen „erweitert“ wurde, woraus sich ein erweitertes Sternschema ergibt.
Durch das erweiterte Stern-Schema können die Stammdaten von verschiedenen InfoCubes verwendet werden. Die Stammdaten sind InfoCube-unabhängig und können von mehreren Queries aus mehreren verschiedenen InfoCubes heraus gleichzeitig verwendet werden.

Erweitertes Stern-Schema
In einem InfoCube gibt es zwei Faktentabellen: die „normale“ Tabelle (F-Tabelle) und eine komprimierte Tabelle (E-Tabelle). Die Fakten (Kennzahlten) werden durch die Komprimierung von der F-Tabelle in die E-Tabelle geladen. Dabei werden die Request-IDs sowie eventuelle Nullsätze gelöscht. Eine Faktentabelle hat bis zu 16 Schlüsselfelder beziehungsweise Dimensionen. Von diesen sind drei bereits vorbelegt: Zeit, Einheit (Währung oder Mengeneinheit) und Paket. Die restlichen 13 Dimensionen können beliebig gestaltet werden.
Für jede Dimension wird eine Dimensionstabelle mit einem künstlichen Schlüssel generiert, der DIM-ID. In dieser Dimensionstabelle sind weitere künstliche Stammdatenschlüssel (SID) abgelegt. Über die SID-Tabelle gelangen Sie zu den Merkmalsschlüsseln, die für Anzeige-Attribute und Texte benötigt werden. Die SID-Tabellen verknüpfen also die Dimensionstabellen mit ihren jeweiligen Stammdatentabellen.
Die Stammdatentabellen für Navigationsattribute werden direkt über die SID ermittelt. Sie können auch sogenannte Line-Item-Dimensionen erstellen. Dabei wird die SID direkt in der Faktentabelle abgelegt, wodurch sich der Zugriff auf die Daten sehr viel effizienter erfolgt. Die Line-Item-Dimension kann jedoch nur ein Merkmal enthalten.
Die beschreibenden Dimensionstabellen sind also sternförmig um eine zentrale Faktentabelle angeordnet. Die Faktentabelle beschreibt die Kennzahlen und deren direkte Zuordnung zu allen wesentlichen Entitäten. Die Dimensionstabellen beschreiben diese Entitäten näher und liefern weitere Zusatzinformationen. Da die Faktentabelle die eigentlichen Geschäftsvorfälle beschreibt und die Dimensionstabellen nur erklärende Informationen liefern, hat die Faktentabelle im Verhältnis zu den Dimensionstabellen deutlich mehr Einträge. Da mit den Selektionskriterien der Abfrage zuerst auf den kleinen Datenbanktabellen (Dimensionstabellen) eine Vorselektion von relevanten Entitätenschlüsselwerten stattfinden kann, ist die Datenabfrage performant möglich. Eine Zusammenführung (Join) mit der großen Faktentabelle erfolgt nur für die relevanten Datensätze. Dieser Vorteil geht jedoch verloren, wenn aufgrund unpassender Modellierung eine oder mehrere Dimensionstabellen im Verhältnis zur Faktentabelle zu groß werden. Die Modellierung kleiner Dimensionstabellen ist also entscheidend für die Performance.
Daneben sollten Sie die folgenden Möglichkeiten nutzen, um den Cube noch performanter zu gestalten:
- Modellierung kleiner Dimensionstabellen
- Bildung von Aggregaten
- Komprimierung
- Partitionierung
- Geeignete Parametrisierung des OLAP Cache

Planung und Reporting mit SAP Analysis leicht gemacht!
Lernen Sie, wie Sie mit SAP Analysis for Microsoft Office professionelle Berichte erstellen. Dieses Praxishandbuch erklärt Ihnen, wie Sie Ihre Daten auf vielfältige Weise auswerten und darstellen. Schritt-für-Schritt-Anleitungen mit zahlreichen Screenshots unterstützen Sie – von der Implementierung bis zur Anwendung.
Modellierungsregeln
InfoCube-Umfang
Je stärker sich der Umfang eines InfoCubes für einen Analysezweck reduzieren lässt, desto besser. Je weniger granular die Daten vorliegen, desto schlanker und somit auch performanter können Sie den InfoCube modellieren. Sie müssen also nicht alle InfoObjekte, die in den Berichtsanforderungen beschrieben sind, als Merkmal in den InfoCube aufnehmen. Die Aufnahme ist nur dann erforderlich, wenn sich Stammdaten ändern können und Sie später eine Auswertung mit dem Stand des Bezugsmonats ausführen möchten. Es kann auch eine Modellierung als Anzeigeattribut ausreichend sein. Eine genaue Analyse der Anforderungen des Anwenders ist sehr wichtig. In der Unkenntnis der genauen Anforderungen einfach alle verfügbaren Merkmale und Kennzahlen in den InfoCube aufzunehmen, wäre eine schlechte Lösung. Sie liefen dabei Gefahr, dass das System später unter mangelnder Akzeptanz leiden könnte.
Analysieren Sie die Anforderungen des Anwenders daher sehr genau. Stellen Sie sicher, dass nur absolut notwendige InfoObjekte in den InfoCube aufgenommen werden.
Aufteilung der Berichtsanforderungen
Die an Sie von der Fachabteilung herangetragenen Berichtsanforderungen sind nicht unbedingt in Form eines InfoCubes umzusetzen. Analysieren Sie zunächst, welche Prozesse und Themen relevant sind und welche Kennzahlen und Merkmalen je Prozess benötigt werden. Hieraus leiten Sie die Anforderung für einen oder mehrere InfoCubes ab.
Daten werden nur dann zusammengeführt und in einem Cube modelliert, wenn die Möglichkeiten von MultiProvidern zur Bildung der gemeinsamen Analysesicht auf die Daten nicht mehr ausreichend sind. Das Mischen von Merkmalen und Kennzahlen mit unterschiedlichem Prozess- oder Themenbezug in einem Datenbestand führt zu schwer verständlichen Datenmodellen und sollte nach Möglichkeit vermieden werden.
Verwendung von Dimensionen
Der erste Schritt bei der Modellierung eines InfoCubes ist die Überlegung, wie viele Dimensionen für die aufzunehmenden InfoObjekte vorzusehen sind. Dabei können 13 Dimensionen frei verwendet werden. Geizen Sie nicht mit der Verwendung von Dimensionen, denn es macht wenig Sinn, alle InfoObjekte in wenige Dimensionen zu pressen. Falls Sie Ihr BW nach LSA-Modellierungsprinzipien aufgebaut haben, verfügen Sie im Data Propagation Layer über eine Datenbasis, die es Ihnen erlaubt, den Info-Cube zu leeren, ihn zu remodellieren und die Daten ohne Verlust innerhalb kurzer Zeit neu zu laden. In diesem Fall können Sie es sich eher erlauben, von Anfang an bei der Modellierung viele Dimensionen zu verbrauchen.
Die Hauptaufgabe bei der Modellierung des InfoCubes besteht in der Verteilung der InfoObjekte auf die Dimensionen. Die Verteilung auf die Dimensionen und damit der Bedarf an diesen ergibt sich aus dem Bezug der InfoObjekte zueinander (Kardinalitäten, Anzahl der an einer Beziehung beteiligten Entitäten).
Beachten Sie dabei folgende Regeln:
- Zwei InfoObjekte, die in einer n:m-Beziehung zueinander stehen, sollten nicht in eine Dimension aufgenommen werden. So sollten Sie zum Beispiel Kunden- und Materialnummer nicht in derselben Dimension ablegen. Denn in den meisten Unternehmen besteht zwischen der gleichen Kunden- und Materialnummer eine n:m-Beziehung. Die generierte Dimension wäre also zu groß.
- Zwei InfoObjekte, die in einer 1:n-Beziehung zueinander stehen, sollten zusammen in eine Dimension aufgenommen werden.
- Ein InfoObjekt mit einer sehr großen Anzahl an Ausprägungen sollte nach Möglichkeit separat in eine Dimension aufgenommen werden. Keinesfalls aber sollte dieses InfoObjekt mit anderen InfoObjekten kombiniert werden, mit denen es in einer n:m-Beziehung steht.
Es ist nicht möglich, die Dimensionierungsregeln ad hoc immer optimal und vollständig zu berücksichtigen. Nehmen Sie daher eine erste Dimensionierung des InfoCubes vor dem Hintergrund Ihrer Kenntnisse des Themenbereichs vor. Prüfen Sie anschließend das Ergebnis Ihrer Aufteilung, indem Sie Daten laden. Dabei sind natürlich aussagekräftige Daten vorausgesetzt. Nach dem Laden der Daten können Sie das Ergebnis Ihrer Modellierung mit dem Programm SAP_INFOCUBE_DESIGNS (Transaktion SE38) überprüfen. Diesen Report sollten Sie in regelmäßigen Abständen ausführen und Ihre InfoCubes erforderlichenfalls neu dimensionieren.
Satzverhältnis in Dimensions- und Faktentabelle
Diese Regeln dienen nur einem Ziel – die Dimensionstabellen des InfoCubes klein zu halten. Nur auf diese Weise können die Daten des InfoCubes schnell gelesen werden. Die Faustregel besagt, dass die Anzahl der Sätze in einer Dimension idealerweise nicht mehr als 20% der Anzahl der Sätze der Faktentabelle umfassen sollte.
Allerdings werden Sie feststellen, dass dies häufig nicht umsetzbar ist. Denn es gibt Geschäftsprozesse, für die sich diese Regel nicht einhalten lässt. Sollte zum Beispiel Ihr Modell eine Transaktions-ID umfassen, so ist Ihre Dimensionstabelle möglicherweise genauso lang wie die Faktentabelle selbst.
Line Item und hohe Kardinalität
Hohe Kardinalität weist in einer Datenbanktabelle Spalten mit sehr wenigen Duplikaten oder mit eindeutigen Werten aus. Spalten mit hoher Kardinalität sind beispielsweise solche, die Bestellnummern, Benutzernamen oder Benutzer-IDs speichern. Je geringer die Kardinalität der Spalte einer Datenbanktabelle, desto mehr Duplikate oder NULL-Werte gibt es in dieser Spalte.
Sollte sich bei Ihrer Modellierung herausstellen, dass Sie eine Dimension mit hoher Kardinalität modellieren müssen, so bietet Ihnen das SAP BW System zwei Einstellungsmöglichkeiten, die zu einer optimierten Ablage der Daten führen.
Falls Ihre Dimension mehrere InfoObjekte umfasst, so können Sie die Einstellung Hohe Kardinalität wählen. Diese Einstellung ist ab einem Größenverhältnis der Dimensionstabelle zur Faktentabelle von 20% und mehr zu empfehlen. Testen Sie es mit dem Programm SAP_INFOCUBE_DESIGNS, Transaktion SE38. Mit dieser Einstellung kann das System einen geeigneten Index verwenden.
Noch besser ist es, wenn sich ein InfoObjekt mit vielen Ausprägungen (Bestellnummer, IDs) in einer Dimension isolieren lässt. In einem solchen Fall kann die Einstellung Line Item Dimension verwendet werden. Mit dieser Einstellung wird keine Dimensionstabelle angelegt. Die SID-Tabelle des Merkmals übernimmt die Rolle der Dimensionstabelle. Es fällt also eine Tabelle weg und bei der Abfrage werden weniger Tabellen zusammengeführt. Die Performance steigt. Es gibt aber auch einen Nachteil: eine Line-Item-Dimension kann nachträglich nicht um weitere InfoObjekte erweitert werden.
Reihenfolge der InfoObjekte in einer Dimension
Auch die Reihenfolge der InfoObjekte innerhalb einer Dimension kann Einfluss auf die Abfragegeschwindigkeit des InfoCubes haben. Wählen Sie die Reihenfolge der InfoObjekte so, dass das InfoObjekt mit den wenigsten Merkmalsausprägungen an erster Stelle steht. Wenn Sie wissen, dass zwischen den InfoObjekten ein hierarchischer Zusammenhang besteht, bilden Sie diesen über die Reihenfolge der InfoObjekte ab.
Ihre User beklagen sich über langsame Berichte?
- In meinem Newsletter lernen Sie, wie Sie Abhilfe schaffen.
- Entdecken Sie die Möglichkeiten der Performanceoptimierung.
- Praktische Anleitungen ermöglichen Ihnen schnelle Erfolge bei der Optimierung von SAP Systemen.
- Viele Tipps und Tricks zu SAP BI Themen.
- Holen Sie die maximale Performance aus Ihrem SAP BI!
- Bei der Anmeldung zu meinem Newsletter erhalten Sie das Buch „High Performance SAP BI“ als Willkommensgeschenk.

Quellen
Frank Wolf, Stefan Yamada (2010): Datenmodellierung in SAP NetWeaver BW, 1. Auflage, Bonn
Kardinalität (Datenbanken)
Kardinalität (Datenbankmodellierung)
Falls Ihnen dieser Beitrag weitergeholfen hat, wäre es eine sehr nette Anerkennung meiner Arbeit wenn Sie z.B. Ihre Bücher über Amazon bestellen würden. Wenn Sie ein Produkt kaufen, erhalte ich dafür eine Provision. Für Sie ändert sich am Preis des Produktes gar nichts. Ich möchte mich an dieser Stelle jetzt schon für Ihre Unterstützung bedanken.
















Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!