Wie Sie eine SAP Tabelle anlegen

Dieser Beitrag ist Teil des Kurses ABAP Grundlagen.
Warum sollten wir überhaupt Daten speichern? Schließlich können die Benutzer doch die Daten immer wieder eingeben. Nun, wenn Sie mit den Anwendern sprechen, werden diese nicht gerade begeistert sein. Daher müssen wir uns mit der Datenhaltung und Datenbanken auseinander setzen.
In diesem Artikel erläutere ich zunächst die Theorie und zeige dann in der Praxis wie Sie eine Tabelle in SAP anlegen und was Sie dabei beachten müssen.
Wenn wir im SAP Kontext von der Datenbank sprechen ist damit ein relationales Datenbanksystem gemeint. In diesem System werden die Daten durch Tabellen abgebildet. Bei Tabellen handelt es sich um zweidimensionale Datenbehälter die aus Spalten und Zeilen bestehen. Pro Zeile wird ein Datensatz abgelegt, wobei die Datensätze immer gleich aufgebaut sind. Dies wird durch die Spaltenstruktur bestimmt. Mithilfe eines sogenannten Schlüssels (Primärschlüssels, um genau zu sein) kann man einen bestimmten Datensatz finden. Das heißt, dass über den Primärschlüssel ein Eintrag in einer Tabelle eindeutig identifiziert werden kann.

Da SAP sich nicht von einem bestimmten Datenbank Anbieter abhängig machen möchte, arbeitet das System mit sogenannten transparenten Tabellen. Diese ist lediglich die Beschreibung der Tabelle, aber nicht die Tabelle selbst. Mithilfe der transparenten Tabelle wird die Datenbanktabelle angelegt. Wenn Sie die transparente Tabelle aktivieren, wird die Datenbank Tabelle im darunterliegenden DB-System physisch angelegt. (Dabei schickt das SAP-System ein CREATE TABLE Befehl an das Datenbanksystem.)
Man kann es mit der Objektorientierung vergleichen. Es gibt eine Klasse (Beschreibung) und basierend darauf werden die Objekte (Konkretisierung) angelegt.
Die Datenbanktabelle, die automatisch erzeugt wird, hat den gleichen Namen wie die transparente Tabelle. Darüber hinaus hat sie auch die gleiche Struktur: die gleiche Anzahl an Spalten und die Spalten haben die gleichen Namen, wie in der transparenten Tabelle festgelegt. Man schaut quasi durch die transparente Tabelle auf die Datenbanktabelle.
Wenn Sie nun bei einer Programmausführung einen Open-SQL Befehl benutzen, wird diese an die Datenbankschnittstelle übergeben. Die Datenbankschnittstelle übersetzt diese in eine Native-SQL Anweisung. Dabei wird die transparente Tabelle aus dem Dictionary benutzt, die die Datenbanktabelle beschreibt. Die Datenbankschnittstelle reicht anschließend die Native-SQL Anweisung an das Datenbanksystem weiter.
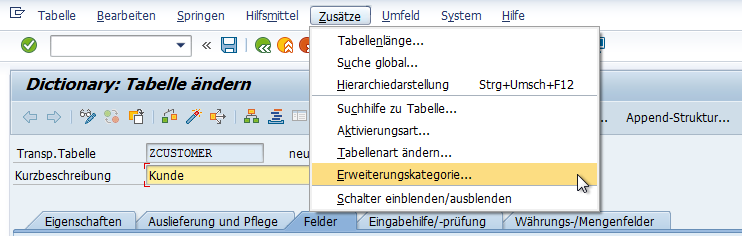
Schluss mit der grauen Theorie. Nun wollen wir eine Tabelle im SAP System anlegen. Dazu legen wir eine Datenbanktabelle und Tabellenfelder in der Transaktion SE11 an. Danach pflegen wir die technischen Einstellungen über den Menüeintrag Springen → Technische Einstellungen. Dann wählen wir eine Erweiterungskategorie über den Menüeintrag Zusätze → Erweiterungskategorie aus.
Außerdem können Sie Sekundärindizes über Springen → Indizes anlegen. Falls benötigt, können Sie Fremdschlüsselbeziehungen der Tabelle zu anderen Tabellen bestimmen. Doppelklicken Sie einfach auf das Feld, welches Sie prüfen möchten.
Wir beginnen die Definition der Tabelle in der Transaktion SE11 (ABAP Dictionary). Wählen Sie den Radiobutton Datenbanktabelle aus und geben Sie den Namen der Tabelle an. Zum Beispiel ZCUSTOMER.
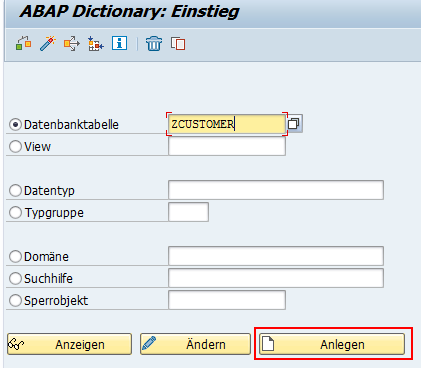
Klicken Sie nun auf den Button Anlegen oder drücken Sie F5. Geben Sie nun im Feld Kurzbeschreibung die Beschreibung ein. Wählen Sie danach bitte A (Anwendungstabelle, Stamm- und Bewegungsdaten) als Auslieferungsklasse aus. Damit wir später Daten einpflegen können (z.B. über Transaktionen SE16 und SM30), stellen Sie bitte den Wert Anzeige/Pflege erlaubt im Feld Tabellensicht-Pflege ein.
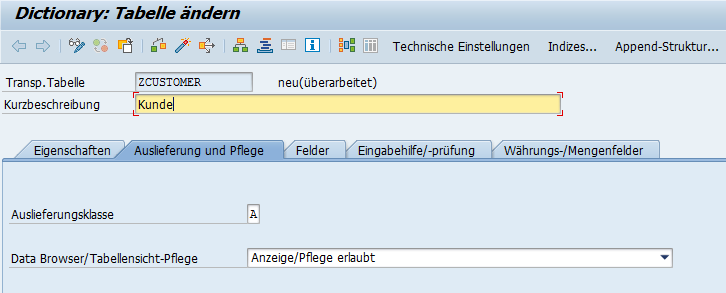
Nun legen wir die Felder der Tabelle an. Wechseln Sie bitte in den Reiter Felder. Hier können Sie die Spalten der anzulegenden Datenbanktabelle definieren.
Im SAP-System gilt das Mandantenkonzept. Ein Mandant ist letztendlich eine Gruppierung von Daten, zum Beispiel von rechtlichen, organisatorischen oder betriebswirtschaftlichen Einheiten. Technische Umsetzung des Mandantenkonzepts äußert sich darin, dass der Mandant als Teil des Primärschlüssels definiert werden muss. Dann werden die Daten mit diesem Mandanten gruppiert. Ob die Daten mandantenabhängig oder mandantenunabhängig sein sollen, wird durch die Spalte MANDT vom Typ MANDT bestimmt.
In diesem Beispiel wollen wir die Daten mandantenabhängig speichern. Daher müssen wir eine Mandatenspalte definieren. Tragen Sie dazu in der ersten Zeile der Spalte Feld den Namen des Felds ein. In diesem Fall MANDT. In der Spalte Datenelement tragen Sie das Datenelement ein. In unserem Fall ebenfalls MANDT.
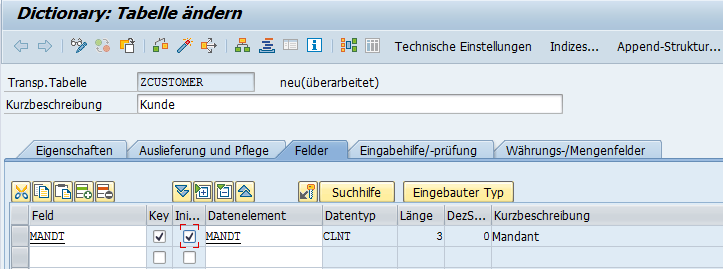
In der Spalte Key können Sie den Primärschlüssel festlegen. Mit diesem können Sie einen Eintrag in der Datenbanktabelle eindeutig auffinden. Eindeutig ist hier das Schlüsselwort, daher sollten Sie bei der Definition des Schlüssels immer auf eine ID zurückgreifen.
Zunächst brauchen wir aber in jedem Fall den Mandanten als Teil des Primärschlüssels. Wir wollen ja die Daten zu einem speziellen Mandanten gruppieren. Daher setzen wir die Key-Checkbox. Darüber hinaus wollen wir, dass ein Initialwert vergeben wird, falls das Feld leer ist. Denken Sie an den zweiten Vornamen eines Kunden. Was soll in der Datenbank angelegt werden, falls der Kunde keinen hat? Daher setzen wir auch die Checkbox bei Initalwerten. Schlüsselfelder werden jedoch ohnehin immer automatisch mit Initialwert belegt.
Anbei finden Sie eine Übersicht über die Initialwerte der verschiedenen Datentypen:
| Datentyp | Initialwert | Bedeutung |
| Numerische Typen | ||
| I | 0 | ganze Zahl |
| F | 0 | Gleitpunktzahl |
| P | 0 | gepackte Zahl |
| Zeichenartige Typen | ||
| C | Leerzeichen | Textfeld (aphanumerische Zeichen) |
| D | 00000000 | Datumsfeld (Format JJJJMMTT) |
| N | 0…0 | numerische Zeichen |
| T | 000000 | Zeitfeld (Format HHMMSS) |
| Variable Länge | ||
| STRING | Zeichenfolge | |
Wie schon angesprochen sollte ein Eintrag in der Tabelle eindeutig identifizierbar sein. Leider reichen Vor- und Nachnamen dazu nicht aus. Denken Sie dabei an häufige Namen wie Schmidt, Müller oder Becker. Eine Lösung könnte darin bestehen, ein zusätzliches Feld zu definieren, welches garantiert eindeutig ist. Zum Beispiel Kunden-ID (Kundennummer).
Daher tragen wir den Namen des Feldes, zum Beispiel CUSTOMERID ein, setzen die Checkboxen Key und Initialwert und anschließend den Namen des Datenelements angeben. Diesen können Sie vorher anlegen oder einfach den Namen in das Datenelement-Feld eingeben und mit der ENTER Taste bestätigen. Anschließend legen Sie das Datenelement mit einem Doppelklick an (Prinzip der Vorwärtsnavigation).
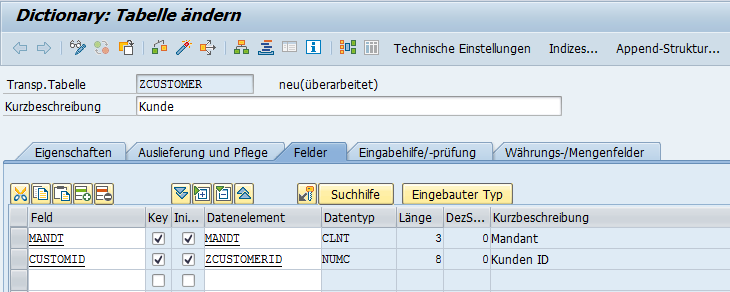
Wiederholen Sie die Prozedur nun um die Felder Vorname und Nachname zu definieren. Tragen Sie einfach den Namen des gewünschten Datenelements in die Spalte ein und klicken Sie ihn doppelt an. Damit starten Sie die Anlage über die Vorwärtsnavigation. Es bietet sich an in der Domäne das Häkchen bei Kleinbuchstaben zu setzen. Die finale Tabelle sieht nun so aus:
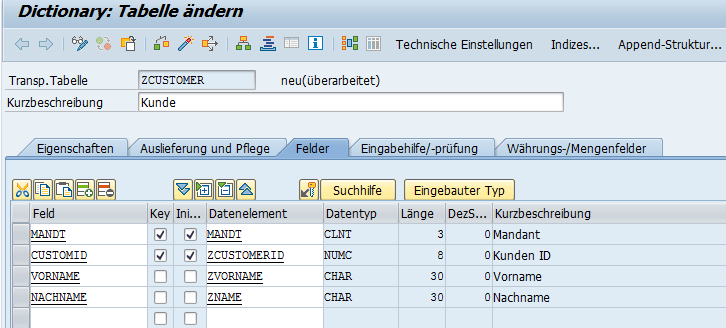
Als Nächstes pflegen wir die technischen Einstellungen. Diese dienen dazu den Platzbedarf und das Zugriffsverhalten der Datenbanktabelle zu optimieren. Wechseln Sie bitte über die Drucktaste Technsiche Einstellungen in die Detailsicht.
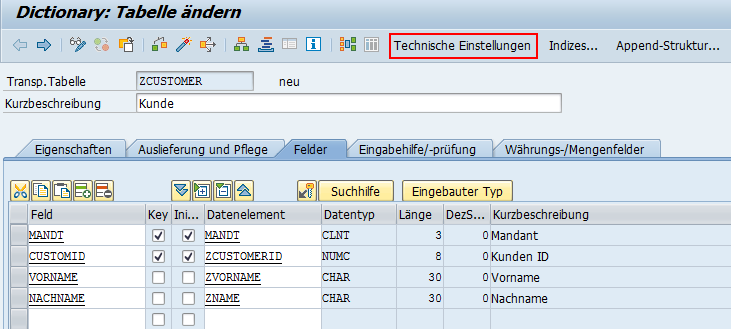
Als Erstes pflegen wir den Parameter Datenart in der Gruppe Logische Speicher-Parameter. Damit können wir steuern, in welchem physischen Bereich der Datenbank unsere Tabelle angelegt wird. Da unsere Daten einmal angelegt und später selten geändert werden, wählen wir die Datenart für Stammdaten, APPL0, aus.
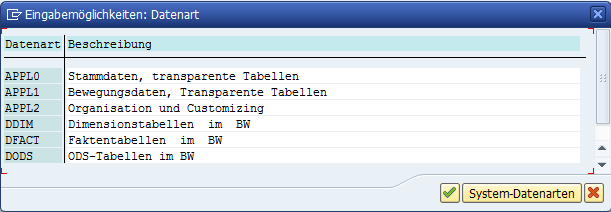
In der Einstellung Größenkategorie können Sie die zu erwartenden Datensätze in der Tabelle festlegen. Das System definiert beim Anlegen der Tabelle eine initiale Platzgröße, den sogenannten INITIAL-Extent. Falls mehr Speicherplatz benötigt wird, fügt das System zusätzlichen Platz hinzu. Dieser neuer Block wird ebenfalls durch die gewählte Kategorie bestimmt und wir als NEXT-Extent bezeichnet. Für unsere Zwecke reicht die Größenkategorie 0 aus.
Ferner können Sie im Abschnitt Pufferung festlegen, ob und was im Tabellenpuffer auf dem Applikationsserver abgelegt wird. Die Pufferung bringt einen Zeitvorteil. Dieser geht allerdings auf Kosten von Ressourcenverfügbarkeit. Überlegen Sie sich daher immer, ob Sie die Pufferung einschalten wollen. So ist die Pufferung von Daten, die sich häufig ändern nicht sinnvoll. Auch bei Daten, die immer aktuell sein müssen, ist von einer Pufferung abzuraten. Wenn Sie sich für eine Pufferung entscheiden, können Sie im Abschnitt Pufferungsart festlegen, ob alle Daten der Tabelle oder nur ein Teil gepuffert wird.
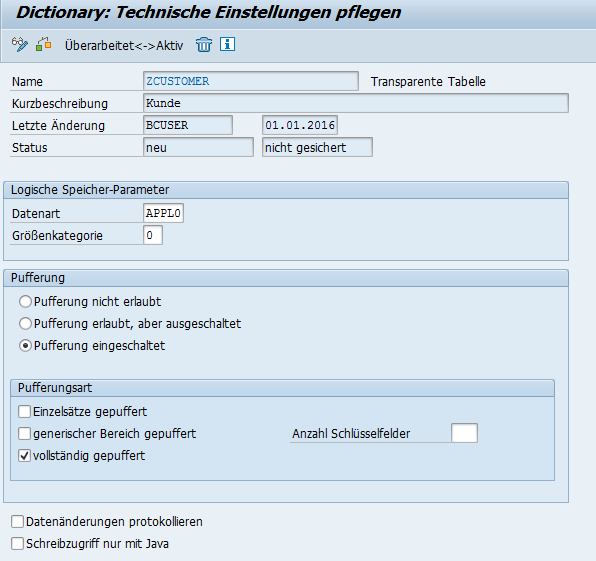
Mit der Checkbox Datenänderungen protokollieren können Sie festlegen, dass jede Veränderung der Daten protokolliert wird. Das Protokoll können Sie in der Transaktion SCU3 auswerten. Allerdings verlangsamt dieses Feature die ändernde Zugriffe.
Sichern Sie nun Ihre Einstellungen und kehren Sie zur Tabelle zurück (F3).
Zu guter Letzt muss die Erweiterungskategorie bestimmt werden. Die Erweiterungskategorie legt fest, ob und wie die Tabelle mit dem Hintergrund der Unicode-Prüfung erweitert werden kann. Wenn keine Erweiterungskategorie festgelegt wird, kann es bei Programmausführung zu Syntax- und Laufzeitfehlern führen. Wählen Sie daher immer eine Erweiterungskategorie aus. Folgende Erweiterungskategorien sind möglich:
- beliebig erweiterbar: Die Struktur und deren Erweiterung darf Komponenten enthalten, deren Datentyp beliebig ist.
- erweiterbar und zeichenartig oder numerisch: Die Struktur und deren Erweiterung darf keine tiefen Datentypen (Tabellen, Referenzen, Strings) enthalten.
- erweiterbar und zeichenartig: Alle Strukturkomponenten und deren Erweiterungen müssen zeichenartig (C, N, D oder T) sein. Die Ausgangsstruktur und alle Erweiterungen durch Customizing-Includes oder durch Append-Strukturen unterliegen dieser Einschränkung.
- nicht erweiterbar: Die Struktur darf nicht erweitert werden.
- nicht klassifiziert: diese Einstellung kann bei Programmen zu Syntax- und Laufzeitfehlern führen, daher sollten Sie immer eine Erweiterungskategorie festlegen.
Um eine Erweiterungskategorie festzulegen gehen Sie bitte auf das Menü Zusätze und wählen Sie anschließend Erweiterungskategorie aus.
Wählen Sie bitte beliebig erweiterbar aus und bestätigen Sie die Auswahl mit Übernehmen. Nun können Sie die Tabelle aktivieren (STRG+F3) und verwenden.
In der neu angelegten Tabelle wird anhand der Schlüsselfelder automatisch ein Primärschlüssel erzeugt. Dieser dient zum Auffinden von Einträgen. Basierend auf dem Primärschlüssel wird ein Primärindex erzeugt. Bei einem Index handelt es sich um einen redundanten Datenbestand, dieser besteht nur aus den Schlüsselfelddaten und wird sortiert abgelegt. Das macht die Suche nach den Datensätzen viel effizienter. Wenn Sie aber nach einem Wert eines Feldes suchen, welches nicht im Schlüssel ist, dauert es gegebenenfalls länger.
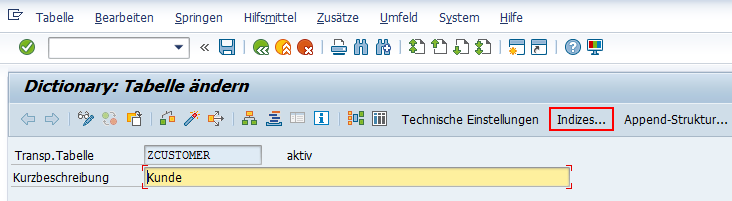
Mit Sekundärindizes können Sie dieses Problem umgehen und sortierte Datenbestände für ausgewählter Felder definieren. Allerdings müssen dabei zusätzliche Daten auf der Datenbank angelegt und sortiert werden. Stimmen Sie sich daher immer mit dem Datenbank-Administrator ab.
So wird wohl in einer Kundentabelle oft nach dem Nachnamen gesucht. Ich selbst habe nicht immer meine Kundennummer zur Hand. Daher definieren wir über den Button Indizes (STRG+F5) einen neuen Index.
Es öffnet sich ein Pop-up mit den bereits definierten Sekundärindizes. Zwar sind noch keine vorhanden, aber wir legen einen neuen über den Eintrag Index anlegen der Anlegen Drucktaste an.
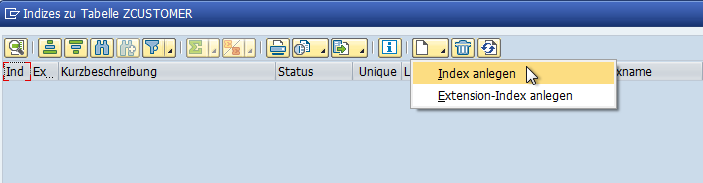
Geben Sie bitte einen Namen für den Sekundärindex an und bestätigen Sie mit dem grünen Häkchen.
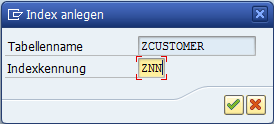
Geben Sie nun bitte eine Kurzbeschreibung an. Außerdem können Sie Ziel-Datenbanken auswählen, auf denen der Index generiert werden soll. Darüber hinaus können Sie festlegen, dass die ausgewählten Felder bereits einen Eintrag in der Datenbank-Tabelle eindeutig charakterisieren. Bei einem Nachnamen ist es nicht der Fall (denken Sie an Müller, Schmidt und Becker).
Im Bereich Indexfelder können Sie festlegen, für welcher Felder der Index erzeugt werden soll. Wir wählen das Feld NACHNAME aus. Damit läuft die Suche nach den Nachnamen viel schneller.
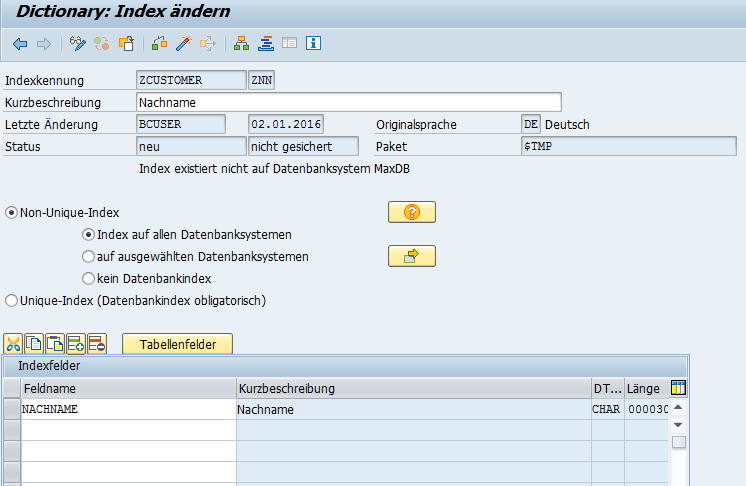
Aktivieren Sie bitte den Index und kehren Sie zur Tabellendefinition zurück. Der Index erscheint nun auch im Menüeintrag Hilfsmittel → Datenbankobjekt → Anzeigen. Hier haben Sie eine Übersicht über alle Felder und Indizes der Tabelle.
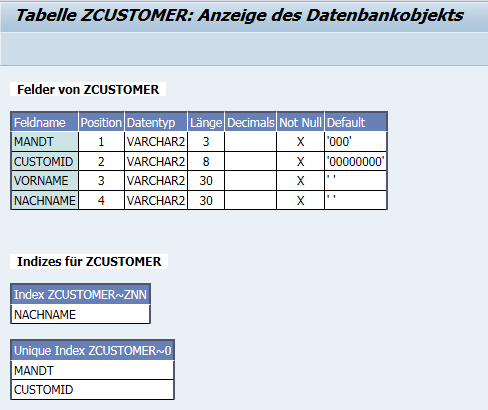
Wenn wir sicherstellen wollen, dass nur die gültigen Mandanten MANDT in unsere Tabelle aufgenommen werden, können wir eine Werteprüfung festlegen. Dafür muss zunächst ein Fremdschlüssel generiert werden. In diesem Fall dient die Tabelle mit den gültigen Mandanten (T000) als Prüftabelle für die Kundentabelle. Die Kundentabelle nimmt in diesem Fall die Rolle der Fremdschlüsseltabelle ein.
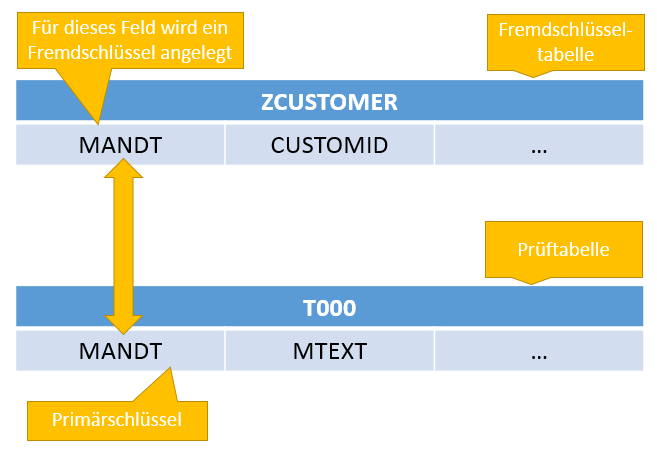
Ein weiteres Beispiel – stellen Sie sich vor, dass Sie eine Party organisieren. Um die Party zu verwalten legen Sie zwei Tabellen ein. Es gibt eine Tabelle mit Freunden und Freundinnen. Das ist die Prüftabelle. Und es gibt eine Tabelle eine Partytabelle, die in diesem Fall als Fremdschlüsseltabelle bezeichnet wird. Wenn Sie nun Gäste für die Party auswählen darf jemand, der nicht in der Freunde-Tabelle ist, leider nicht an der Party teilnehmen.
Um einen Fremdschlüssel zu definieren, klicken Sie doppelt auf das Feld MANDT und klicken Sie anschließend auf das Schlüsselsymbol.
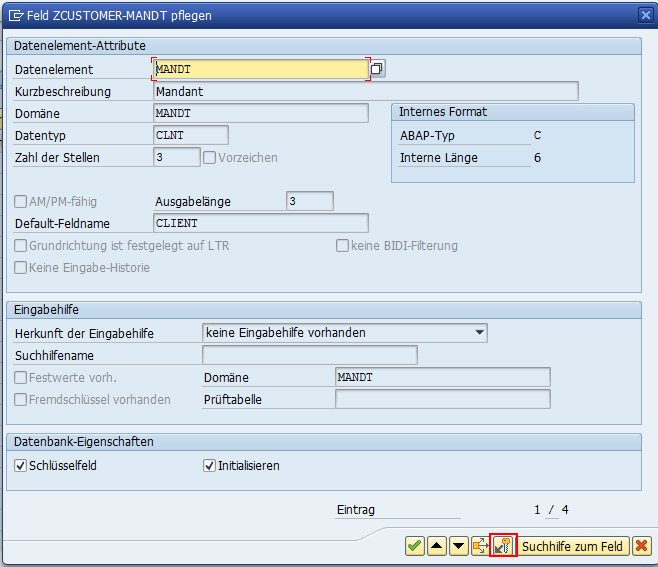
Sie können auch in der Tabellenübersicht das Feld auswählen und auf das Schlüsselsymbol klicken. Ein dritter Weg führt über den Reiter Eingabehilfe/ -prüfung.
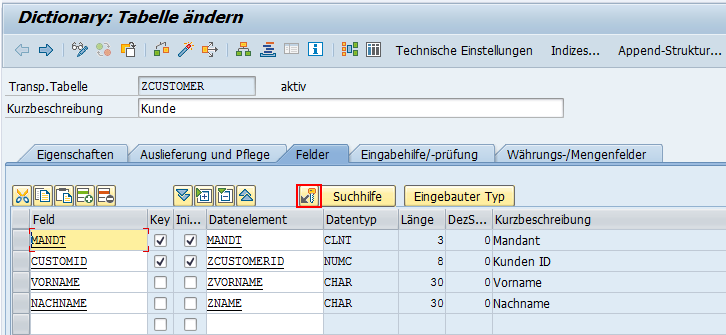
Das System schlägt automatisch die Tabelle T000 als Prüftabelle vor.
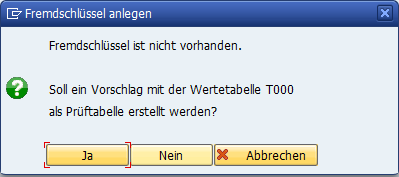
Wie kommt das? Nun, das System schlägt die Prüftabelle anhand der zugrunde liegenden Wertetabelle in der Domäne des Feldes vor. Das Feld MANDT basiert auf dem Datenelement MANDTMANDT basiert. Wenn Sie sich den Reiter Wertebereich der Domäne anschauen, sehen Sie im Abschnitt Wertetabelle die Tabelle T000.
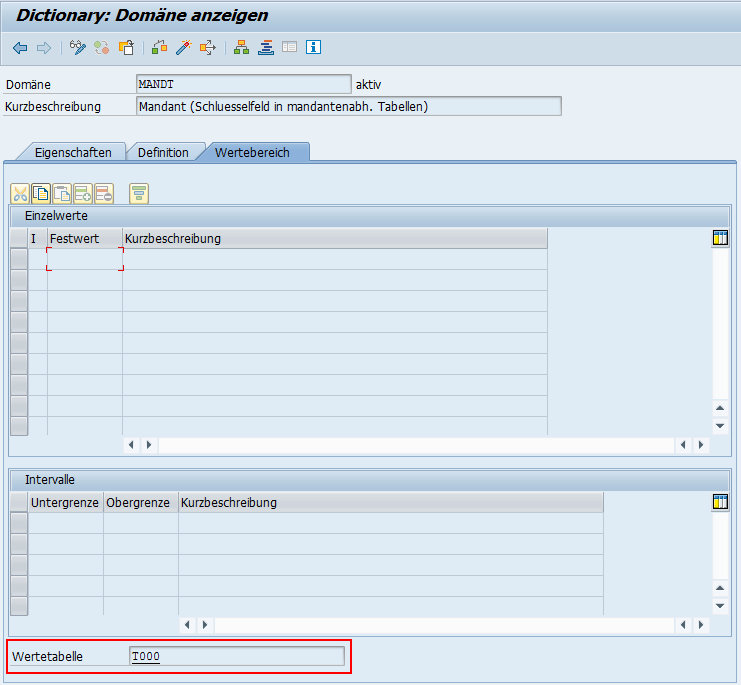
Wir übernehmen also den Systemvorschlag. Im Feld Prüftabelle wir automatisch die Tabelle mit den Werten angezeigt. Im Abschnitt Fremdschlüsselfelder sehen Sie diejenigen Felder, die die Verknüpfung von der Fremdschlüsseltabelle mit der Prüftabelle definieren. Je nachdem, wie viele Felder nötig sind, um einen Eintrag in der Prüftabelle eindeutig zu identifizieren können es auch mehrere Felder sein.
Anschließend können Sie Einstellungen für Dynpros (dynamisches Programm mit grafischen Oberflächen) vergeben, wo dieses Feld verwendet wird.
Im letzten Abschnitt, Semantische Eigenschaften können Sie die Art der Fremdschlüsselfelder und die Kardinalität festlegen. In unserem Fall ist das Feld MANDT ein Teil des Primärschlüssels. Die Kardinalität wird aus Sicht der Prüftabelle beschrieben. Es muss auf jeden Fall ein Wert für den Mandanten vorliegen, daher die 1. Ein Eintrag in der Prüftabelle kann beliebig viele Einträge in der Fremdschlüsseltabelle haben. Also wählen wir CN aus.
Bestätigen Sie bitte die Änderungen mit Übernehmen und aktivieren Sie anschließend die Tabelle. Wenn Sie nun in den Reiter Eingabehilfe/ -prüfung wechseln, wird die Prüftabelle dort angezeigt.
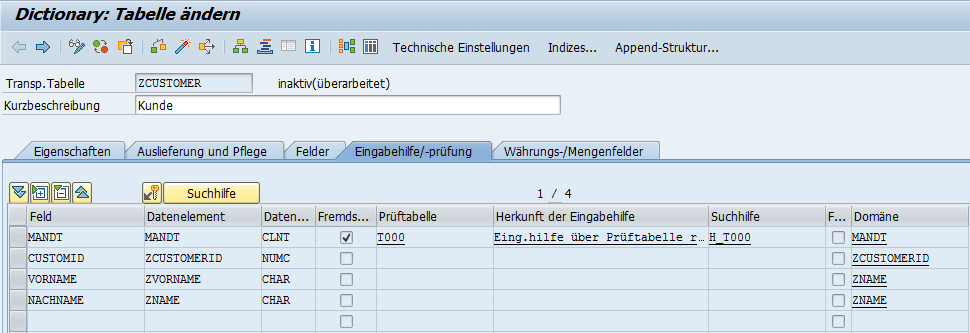
Manchmal reicht allerdings eine Tabelle nicht aus. Denken Sie zum Beispiel an die Adressen der Kunden – ein Kunde könnte ja mehrere Adressen haben.
Nun könnte man in einer Datenbanktabelle pro Zeile den Namen und die Adresse des Kunden eingeben. Falls der Kunde zwei Adressen hat, werden zwei Einträge angelegt, die immer seinen Namen enthalten. Dabei müsste man immer alle Informationen pro Adresse wiederholen. Das geht auch besser.
| Adresse | Vorname | Nachname |
| Gelnhausen | Philipp | Reis |
| Friedrichsdorf | Philipp | Reis |
| Frankfurt am Main | Philipp | Reis |
| Hoyerswerda | Konrad | Zuse |
| Berlin | Konrad | Zuse |
| Edinburgh | Graham | Bell |
Man könnte zum Beispiel die Daten in logische Einhaiten aufteilen. Da ein Kunde viele Adressen haben kann, ist es sinnvoll eine Tabelle für die Kunden und eine für ihre Adressen anzulegen. Zu der Adresse wird immer ein Kunden-Fremdschlüssel (z.B. Kunden-ID) hinterlegt um den Bezug zum Kunden herzustellen.
Die Kundentabelle würde dann wie unsere angelegte Tabelle aussehen:
| Kunden ID | Vorname | Nachname |
| 1 | Philipp | Reis |
| 2 | Konrad | Zuse |
| 3 | Graham | Bell |
In der Adressentabelle würde wie folgt aussehen:
| Adresse ID | Kunden ID | Ort |
| 1 | 1 | Gelnhausen |
| 2 | 1 | Friedrichsdorf |
| 3 | 1 | Frankfurt am Main |
| 4 | 2 | Hoyerswerda |
| 5 | 2 | Berlin |
| 6 | 3 | Edinburgh |
Kunden und Adressen stehen in einer 1:n-Beziehung zu einander. Das heißt, dass ein Kunde beliebig viele Adressen haben kann, aber jede Adresse genau zu einem Kunden gehört.
Dieses Vorgehen hat mehrere Vorteile. Die Daten werden nicht redundant gehalten. Die Vor- und Nachnamen kommen nur in der Kundentabelle vor. Dadurch werden auch Inkonsistenzen vermieden.
Im SAP System sieht das Ganze so aus.
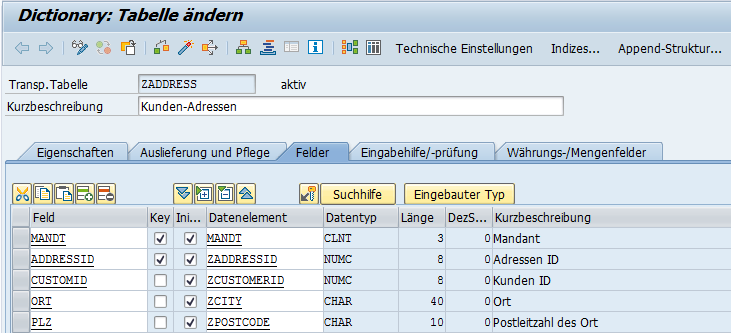
Die Adressen ID (und der Mandant) sind als Schlüsselfelder definiert. Darüber hinaus verfügt die Tabelle über eine Kunden-ID. Über diese können wir einen Fremdschlüsselbezug zum Kunden herstellen.
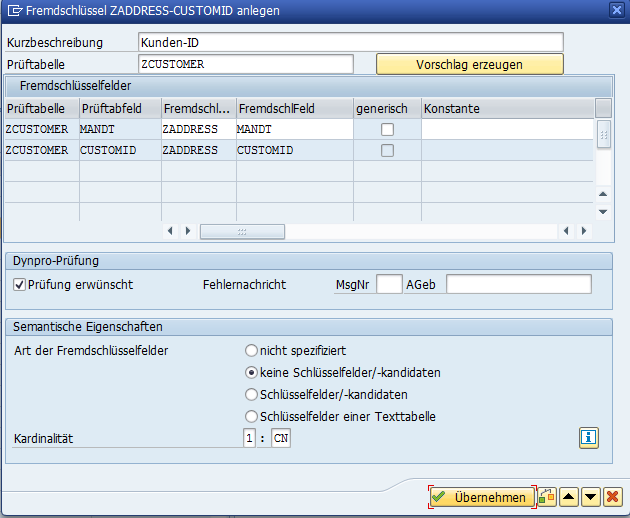
Beachten Sie bitte, dass die Einstellungen für die Kunden-ID sich von dem Mandanten-Beispiel weiter oben unterscheiden. Da der Kunde nicht ein Bestandteil des Schlüssels (für die Adressentabelle) ist, wählen wir keine Schlüsselfelder/-kandidaten aus.
Diese ABAP Tricks machen Ihr Leben leichter!
- In meinem Newsletter gebe ich eine Menge Tipps und Kniffe rund um ABAP.
- Die Mini-Tutorials unterstützen Sie dabei, Software in ABAP effizienter zu entwickeln.
- Praktische Anleitungen ermöglichen Ihnen schnelle Erfolge bei der Optimierung Ihrer Arbeit.
- Bei der Anmeldung zu meinem Newsletter erhalten Sie das Buch „ABAP Tipps und Tricks“ als Willkommensgeschenk.

Quellen und weiterführende Literatur:
Karl-Heinz Kühnhauser, Thorsten Franz (2011): Discover ABAP, 3. Auflage, Bonn
Falls Ihnen dieser Beitrag weitergeholfen hat, wäre es eine sehr nette Anerkennung meiner Arbeit wenn Sie z.B. Ihre Bücher über Amazon bestellen würden. Wenn Sie ein Produkt kaufen, erhalte ich dafür eine Provision. Für Sie ändert sich am Preis des Produktes gar nichts. Ich möchte mich an dieser Stelle jetzt schon für Ihre Unterstützung bedanken.
Bildquelle: Pixabay, CC0 Public Domain






Trackbacks & Pingbacks
[…] Modifizieren von Tabelleninhalten auf der Datenbankebene erfolgt durch Open-SQL-Anweisungen. Dabei handelt es sich um spezielle ABAP […]
[…] Strukturen und Workareas werden auch Open SQL Anweisungen erläutert. Zuvor legen wir jedoch eine Tabelle an. In dem Kapitel Programmablaufsteuerung stelle ich IF und CASE Befehle vor. Anschließend werden […]
[…] Beitrag ist Teil des Kurses ABAP Grundlagen. In einem früheren Artikel habe ich gezeigt, wie Sie eine SAP Tabelle anlegen und was Sie dabei beachten müssen. In diesem […]
Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!