Interne Tabellen in ABAP
Dieser Beitrag ist Teil des Kurses ABAP Grundlagen.
In diesem Artikel stelle ich interne Tabellen vor. Unter anderem gehe ich auf die folgenden Punkte ein:
- Tabellenarten
- Performance
- Beispiele
Neben den Tabellen auf der Datenbank existieren auch Tabellen im Arbeitsspeicher. Diese werden auch als interne Tabellen bezeichnet, da Sie nur zur Laufzeit existieren. Diese internen Tabellen verhalten sich genau wie die in ABAP deklarierte Strukturen. Allerdings hat eine temporäre Struktur (ein Arbeitsbereich) nur eine Zeile, während eine interne Tabelle beliebig viele Zeilen haben könnte.
Wie bei einer Datenbanktabelle haben alle Zeilen denselben Aufbau und dieselbe Struktur. Für die lesende Verarbeitung von Datensätzen muss jeder Datensatz aus dem Tabellenrumpf (dem Inhalt der internen Tabelle) in eine Workarea gestellt werden. Von dort aus erfolgt dann die Weiterverarbeitung. Bei der schreibenden Verarbeitung wird eine Zeile zuerst in der Workarea aufbereitet und anschließend erfolgt die Übertragung an den Tabellenrumpf, indem wir die Workarea anhängen oder einfügen.
Da die internen Tabellen im Arbeitsspeicher liegen, erfolgt der Zugriff um ein vielfaches schneller als der Zugriff auf eine Datenbanktabelle. Allerdings nimmt die Verarbeitungsgeschwindigkeit mit zunehmender Tabellengröße ab. Daher sollten Sie je nach betriebswirtschaftlicher Anforderung und voraussichtlicher Tabellengröße beim Anlegen der internen Tabelle auf den Typ achten.
Insgesamt gibt es drei Tabellentypen: Standardtabellen, sortierte Tabellen und Hash-Tabellen. Dabei werden Standardtabellen und sortierte Tabellen auch als Indextabellen bezeichnet.
Ein wesentliches Unterscheidungsmerkmal ist der Schlüssel. Dieser dient wie bei einer Datenbanktabelle der Identifizierung einer Zeile. Bei internen Tabellen existieren eindeutige UNIQUE und nicht eindeutige NON-UNIQUE Schlüssel. Bei einem eindeutigen Schlüssel können keine mehrfachen Einträge in internen Tabellen vorkommen. Bei einem nicht eindeutigen Schlüssel darf eine Zeile in der internen Tabelle auch mehrfach vorkommen.
Daneben existieren auch benutzerdefinierte Schlüssel. Dieser kann aus einer beliebigen, frei definierbaren Teilmenge von Feldern der Struktur zusammengesetzt werden. Bei der Definition des Schlüssels ist die Reihenfolge der Schlüsselfelder wichtig. Dies von Bedeutung, wenn beispielsweise nach dem Schlüssel sortiert wird.
Die Tabellenart definiert, wie ABAP auf einzelne Tabellenzeilen zugreift.
Tabellenarten
Standardtabellen
Bei Standardtabellen STANDARD TABLE kann der Zugriff über einen Schlüssel oder einen Index erfolgen. Dabei ist der Schlüssel einer Standardtabelle immer nicht eindeutig NON-UNIQUE. Daher können mehrfache identische Zellen vorkommen. Bei dem Zugriff über einen Schlüssel wächst die Zugriffszeit linear. Je mehr Zeilen, desto länger dauert es bis zur Antwort, da häufig die komplette Tabelle durchsucht wird, um den betreffenden Satz zu finden.
Dafür kann die Standardtabelle sehr schnell gefüllt werden, da nicht nach bereits vorhandenen Einträgen gesucht werden muss. So könnte man die Tabelle zuerst füllen und dann entsprechend dem Verwendungszweck sortieren und die Duplikate löschen. Verwendet man danach Schlüsselzugriffe mit der Option für binäre Suche BINARY SEARCH, so steigt der Suchaufwand mit der Anzahl der Tabelleneinträge nur noch logarithmisch.
Bei Standardtabellen wird automatisch ein interner Index SY-TABIX gepflegt. Dieser beinhaltet die Zeilen 1 bis Anzahl der Zeilen. Bei großen internen Tabellen ist eventuell der Zugriff über den Index sinnvoll.
Sortierte Tabellen
Sortierte Tabellen SORTED TABLE werden immer nach dem Schlüssel sortiert abgespeichert. Der Schlüssel kann eindeutig oder nicht-eindeutig sein. Bei der Tabellendefinition muss die Eindeutigkeit des Schlüssels als UNIQUE oder NON-UNIQUE deklariert werden. Beim Schlüsselzugriff hängt die Antwortzeit logarithmisch von der Anzahl der Tabelleneinträge ab, da der Zugriff über eine binäre Suche erfolgt. Allerdings ist der Aufbau von sortierten Tabellen langsamer, da immer die Sortierung eingehalten werden muss. Der Zugriff kann auch über den Tabellenindex erfolgen.
Sortierte Tabellen haben zwei wesentliche Vorteile. Zum einen können Sätze mit doppeltem Schlüssel automatisch verhindert werden. Doppelte Sätze werden bereits beim Füllen der Tabelle erkannt. Je nach Inhalt des Returncodes der ABAP-anweisung und der Gestaltung der Fehlerbehandlung im Coding kann in eine Fehlerbehandlung (z.B. doppelte Sätze überspringen) verzweigt werden oder es wird ein Laufzeitfehler ausgelöst. Zum anderen sind sortierte Tabellen bei Schleifen mit WHERE Bedingungen schneller. Dabei ist die Reihenfolge der Schlüsselfelder wichtig. Diese sollte so gewählt werden, dass möglichst alle Zugriffe die führenden Schlüsselfelder versorgen.
Betrachten wir das folgende Beispiel. Die sortierte Tabelle lt_demo hat die Schlüsselfelder S1, S2, S3 und S4. Dann ist bei gleicher Datenmenge der Befehl
LOOP AT lt_demo WHERE S1 = 'ABC'. ENDLOOP.
deutlich schneller als die ähnliche Anweisung
LOOP AT lt_demo WHERE S2 = 'XYZ' AND S3 = '123' AND S4 = '0'. ENDLOOP.
Bei der ersten Anweisung wird über binäre Suche genau der Anfangspunkt gesucht, bei dem S1 den Wert ABC annimmt. Dann wird die Tabelle so lange zeilenweise abgearbeitet, bis S1 nicht mehr den Wert ABC hat. In diesem Fall hilft die Sortierung der Tabelle alle relevanten Zeilen zu finden.
In der zweiten Anweisung haben wir keine Informationen über S1. Damit ist die bestehende Sortierung der Tabelle nutzlos, es muss die gesamte Tabelle gelesen werden, um die relevanten Zeilen zu finden.
Hash-Tabellen
Bei Hash-Tabellen wird kein Index erzeugt, der Zugriff erfolgt über einen eindeutigen Schlüssel. Der Schlüssel kann aus einem oder auch mehreren Feldern bestehen. Dieser Tabellentyp empfiehlt sich für große Tabellen, da durch den Hash-Algorithmus die Anwortzeit konstant ist. Dabei ist es gleichgültig, wie viele Zeilen die Tabelle hat. Achten Sie darauf, dass der Schlüssel bei Hash-Tabellen eindeutig sein muss und zu Ihrem Lesezugriff passt. Haben Sie z.B. Daten, bei denen Ihr Lesezugriff nicht eindeutig ist, sollten Sie besser nur eine Teilmenge der Daten oder eine sortierte Tabelle verwenden. Mögliche Verwendung im BW wäre zum Beispiel die Anreicherung von Bewegungsdaten.
Performance
Optimale Zugriffe
Welche Tabellenart im Einzelfall schneller ist, hängt wie so oft von diversen Faktoren ab. Insbesondere die Anzahl und die Sortierung der Sätze in der Tabelle spielen eine große Rolle. In der Regel besitzen jedoch Hash-Tabellen einen deutlichen Vorteil gegenüber sortierten Tabellen und diese wiederum gegenüber Standardtabellen. Um immer den optimalen Lesezugriff auf interne Tabellen zu finden, sind in der nachfolgenden Tabelle die möglichen Tabellenzugriffe mit den Auswirkungen auf die Laufzeit dargestellt.
| Zugriffsart | Standardtabelle | Sortierte Tabelle | Hash-Tabelle |
READ TABLE tab |
Die Tabelle wird Zeile für Zeile durchsucht (Full Table Scan): O(n) |
Full Table Scan: O(n) |
Full Table Scan: O(n) |
READ TABLE tab |
Full Table Scan: O(n) |
Es wird mittels binärer Suche gesucht: O(log n) |
Durch ein Hash-Verfahren erfolgt der Zugriff in nahezu konstanter Zeit: O(1) |
READ TABLE tab |
Der Zugriff erfolgt in nahezu konstanter Zeit: O(1) |
Der Zugriff erfolgt in nahezu konstanter Zeit: O(1) |
Nicht möglich |
LOOP AT tab |
Full Table Scan: O(n) |
Enthält die WHERE Bedingung den ersten Teil des Schlüssels, wird binär bis zum Anfangspunkt gesucht. Danach werden nur die Einträge Zeile für Zeile gelesen, die die entsprechenden Werte haben: O(log n + m). (Siehe Beispiel Sortierte Tabellen) Andernfalls wird die gesamte Tabelle Zeile für Zeile durchsucht (Full Table Scan): O(n) |
Full Table Scan: O(n) |
Die O-Notatigion bezieht sich auf den Faktor, um den die Zugriffszeit mit der Größe der Tabelle wächst.
O(1)– Der Zugriff ist rechnerabhängig und wird als konstant betrachtet, die asymptotische Laufzeitkomplexität beträgtO(1).O(n)– Die Zugriffszeit wächst proportional zur Anzahl der Tabelleneinträgen. Je mehr Einträge, desto länger dauert es.O(log n)– Die Zugriffszeit wächst proportional zum Logarithmus der Anzahlnder Einträge. So führt zum Beispiel das Quadrieren der Tabelleneinträgengerade einmal zur Verdoppelung der Laufzeit. So werden bei sortierten Tabellen die Einträge sortiert nach Schlüsselwerten abgelegt. Daher kann das System bei der Suche nach jedem Suchschritt die Hälfte der Werte rausschmeißen.O(log n + m)– Die Zugriffszeit ist proportional zulog n + m, wobeimdie Anzahl der Treffer undndie Anzahl der Tabelleneinträge ist.

Spicker zum Herunterladen
Feldsymbole
Neben den „richtigen“ Tabellenarten und Lesezugriffen bieten Feldsymbole eine weitere Möglichkeit die Performance zu optimieren. Feldsymbole beschleunigen den Programmablauf und helfen Speicherplatz zu sparen. Feldsymbole stellen in ABAP das Äquivalent zu Zeigern in anderen Programmiersprachen dar. Sie enthalten keine physischen Daten, sondern zeigen nur auf Variablen im Arbeitsspeicher, die die Daten enthalten. Technisch beinhaltet ein Zeiger die Speicheradresse, die die Daten enthält.
In der folgenden Übersicht finden Sie die wichtigsten Befehle zur Behandlung von Feldsymbolen.
| Befehl | Bedeutung | Anmerkung |
FIELD-SYMBOLS: <fs> TYPE type. |
Das Feldsymbol wird definiert. | Sie sollten immer typisierte Feldsymbole verwenden. Im Zweifelsfall können Sie Feldsymbole mit dem Typ ANY oder ANY TABLE typisieren. |
ASSIGN var TO <fs>. |
Dem Feldsymbol <fs> wird die Variable var zugewiesen. | Nach dieser Anweisung können Sie statt der Variablen var auch das Feldsymbol <fs> verwenden, bis <fs> einer anderen Variable zugewiesen wird. |
<fs> = 1337. |
Dem Feldsymbol <fs> wird der Wert 1337 zugewiesen. | Wenn die Variable var dem Feldsymbol <fs> zugewiesen ist, nimmt auch var diesen Wert an. |
LOOP AT tab |
Während der Schleife wird dem Feldsymbol <fs> die aktuelle Zeile der Tabelle TAB zugewiesen. | Bei breiten Tabellen ist der Performancevorteil am größten. Generell bringt diese Anweisung ab fünf Schleifendurchläufen Performancevorteile. |
READ TABLE tab ASSIGNING <fs> ... |
Dem Feldsymbol <fs> wird das Ergebnis der Leseanweisung zugewiesen. | Diese Anweisung bietet Performancevorteile ab einer Tabellenlänge von 1.000 Bytes. |
Anbei auch ein Spicker zum Herunterladen.
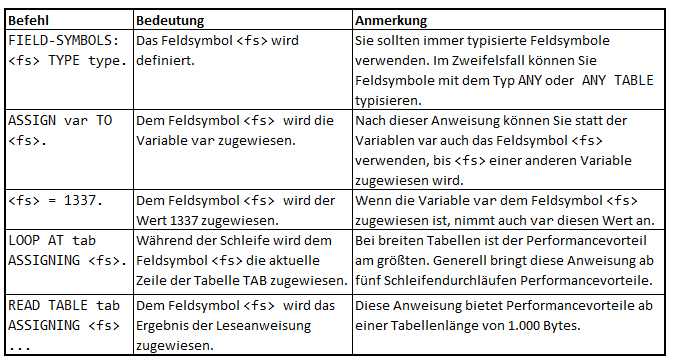
Übersicht über Feldsymbole Befehle
Beispiele
In der Praxis sind die Standardtabellen nach wie vor der häufigste Tabellentyp. Daher beziehen sich die Beispiele in diesem Beitrag auf Standardtabellen.
Interne Tabelle anlegen
Der Prozess für das Anlegen einer internen Tabelle besteht aus drei Schritten:
- Deklaration eines Zeilentyps
- Deklaration der Tabelle
- Deklaration des Arbeitsbereichs
Unsere interne Tabelle soll Smartphones mit ihren Preisen enthalten. Zunächst deklarieren wir den Zeilentyp. Die Deklaration erfolgt über die TYPES Anweisung.
TYPES: BEGIN OF zeile_typ, thandy TYPE zsmartphones2-thandy, tpreis TYPE zsmartphones2-tpreis, END OF zeile_typ.
Unser Zeilentyp besteht aus zwei Feldern thandy und tpreis. Bei der Deklaration verweisen wir auf die Felder bereits vorhandene Tabelle. Alternativ können wir auch auf die jeweiligen Datenelemente verweisen.
TYPES: BEGIN OF zeile_typ, thandy TYPE /bi0/oimaterial, tpreis TYPE /bi0/oiamount, END OF zeile_typ.
Als nächstes wird die Tabelle samt Tabellentyp deklariert. Dabei muss je nach Tabellentyp der Schlüssel festgelegt werden. Optional können Sie über die Anweisung INITIAL SIZE n den Speicherplatz für n Tabellenzeilen vorbelegen. Dies ist nur sinnvoll, wenn Sie bereits die voraussichtliche Anzahl von Zeilen in diesem Tabellentyp genau einschätzen können. Dieser Zusatz kann entfallen, wenn für n der Wert 0 eingesetzt wird und Sie es dem System überlassen wollen, den Speicherplatz zu verwalten.
Mit der folgenden Anweisung deklarieren Sie eine interne Standardtabelle. Dabei legt STANDARD TABLE oder kurz TABLE die Tabellenart fest.
DATA lt_itab TYPE STANDARD TABLE OF zeile_typ.
Eine Standardtabelle hat immer einen nicht eindeutigen Schlüssel, daher kann der Zusatz für den Schlüssel entfallen.
Um eine sortierte Tabelle zu definieren, verwenden Sie die folgende Anweisung. Der Schlüssel von sortierten Tabellen kann eindeutig oder nicht-eindeutig sein.
DATA lt_itab TYPE SORTED TABLE OF zeile_typ
WITH UNIQUE KEY thandy.
Auch bei Hash-Tabellen muss der eindeutige Schlüssel immer explizit angegeben werden.
DATA lt_itab TYPE HASHED TABLE OF zeile_typ
WITH UNIQUE KEY thandy.
Der Schlüssel kann auch mehrere Felder beinhalten, zum Beispiel:
DATA lt_itab TYPE HASHED TABLE OF zeile_typ
WITH UNIQUE KEY thandy tcolor.
Anschließend deklarieren wir den Arbeitsbereich für die interne Tabelle mithilfe des Zeilentyps.
DATA ls_itab TYPE zeile_typ.
Interne Tabelle füllen
Nun zeige ich Ihnen wie Sie ein interne Tabellen füllen können. Dabei gibt es verschiedene Möglichkeiten. Sie können direkt auf die Datensätze der internen Tabelle zugreifen oder mithilfe einer Workarea (bzw. Struktur) arbeiten. Das Arbeiten mit einer eigens dazu angelegten Workarea hat den Vorteil, dass Sie den Datensatz, den Sie in die interne Tabelle einfügen, in Ruhe verarbeiten können.
1. Beispiel
Wir übertragen den Inhalt der Datenbanktabelle ZSMARTPHONES2 zeilenweise in die namensgleichen Felder der Workarea ls_zsmartphones. Die Workarea kann immer nur den Inhalt einer Zeile aufnehmen. Anschließend erfolgt die Zuweisung der Feldinhalte. So entspricht das Feld artikel in unseren internen Tabelle dem Feld thandy auf der Datenbank. Nachdem die Workarea der internen Tabelle gefüllt ist, hängen wir über die Anweisung APPEND die Feldinhalte der Workarea an die interne Tabelle lt_itab.
TYPES: BEGIN OF zeile_typ,
artikel TYPE /bi0/oimaterial,
preis TYPE /bi0/oiamount,
END OF zeile_typ.
DATA: lt_itab TYPE TABLE OF zeile_typ,
ls_itab TYPE zeile_typ,
ls_zsmartphones TYPE zsmartphones2.
SELECT * FROM zsmartphones2 INTO ls_zsmartphones.
ls_itab-artikel = ls_zsmartphones-thandy.
ls_itab-preis = ls_zsmartphones-tpreis.
APPEND ls_itab to lt_itab.
ENDSELECT.
2. Beispiel
In diesem Beispiel übertragen wir den Inhalt der Datenbanktabelle zeilenweise in die namensgleichen Felder der internen Tabelle. Zunächst wird die Workarea der Datenbanktabelle ls_zsmartphones gefüllt. Dort stehen alle Feldinhalte der Datenbankzeile. Wir übertragen aber nur einen Teil davon in die Workarea der internen Tabelle. Nur die namensgleichen Felder werden übernommen. Beachten Sie bitte, dass das System nur die Namensgleichheit prüft, nicht die Gleichheit der Feldeigenschaften. Daher sollten Sie sich bei der Deklarierung der internen Tabelle an den Datenelementen der Datenbanktabelle orientieren.
TYPES: BEGIN OF zeile_typ,
thandy TYPE /bi0/oimaterial,
tpreis TYPE /bi0/oiamount,
END OF zeile_typ.
DATA: lt_itab TYPE TABLE OF zeile_typ,
ls_itab TYPE zeile_typ,
ls_zsmartphones TYPE zsmartphones2.
SELECT * FROM zsmartphones2 INTO ls_zsmartphones.
MOVE-CORRESPONDING ls_zsmartphones TO ls_itab.
APPEND ls_itab TO lt_itab.
ENDSELECT.
3. Beispiel
Sie können den Inhalt der Datenbanktabelle nicht nur zeilenweise, sondern auch blockweise in die interne Tabelle übertragen. Dabei lassen wir die Workareas außen vor. Das ist die schnellste Möglichkeit eine interne Tabelle zu füllen.
In diesem Beispiel übertragen wir alle Inhalte von namensgleichen Feldern mit einem Mal von der Datenbanktabelle in die interne Tabelle.
TYPES: BEGIN OF zeile_typ, thandy TYPE /bi0/oimaterial, tpreis TYPE /bi0/oiamount, END OF zeile_typ. DATA: lt_itab TYPE TABLE OF zeile_typ. SELECT * FROM zsmartphones2 INTO CORRESPONDING FIELDS OF TABLE lt_itab.
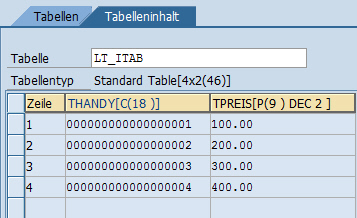
Daten wurden in die interne Tabelle übertragen
Interne Tabelle verarbeiten
Wie auch bei Datenbanktabellen können Sie bei internen Tabellen über eine Schleife alle Zeilen nacheinander oder auch einzelne Zeilen verarbeiten. Allerdings werden in diesem Zusammenhang unterschiedliche Anweisungen verwendet.
LOOP ... ENDLOOP
So wird zum Beispiel für eine Schleife die Anweisung LOOP mit ENDLOOP statt SELECT mit ENDSELECT verwendet. Mit einer Schleife verarbeiten Sie zeilenweise alle Sätze einer Tabelle. Bei der LOOP-Anweisung können Sie die Zeilen der internen Tabelle in eine Workarea stellen. Die Anweisung wird mit ENDLOOP abgeschlossen. Da die Workarea frei wählbar ist, müssen Sie angeben, um welche Workarea es sich handelt.
LOOP AT lt_itab INTO ls_itab. ENDLOOP.
Mit dieser Anweisung wird die Workarea ls_itab bei jedem Schleifendurchlauf mit einer Zeile der Tabelle lt_itab gefüllt.
MODIFY
Innerhalb der Schleife könnten Sie die Einträge ändern. In dem folgenden Beispiel setzen wir den Preis konstant auf 1. Für die Änderung bestehender Einträge der internen Tabelle verwenden wir den Befehl MODIFY. Steht dieser Befehl innerhalb der Schleife, wird die aktuelle Zeile der internen Tabelle im Bezug auf die relevante Workarea aktualisiert.
Zunächst ändern wir den Inhalt der Workarea ls_itab. Anschließend wird die Zeile der internen Tabelle aus (FROM) der Workarea überschrieben.
LOOP AT lt_itab INTO ls_itab. ls_itab-tpreis = 1. MODIFY lt_itab FROM ls_itab. ENDLOOP.
Das Ganze funktioniert natürlich auch über Feldsymbole. Verwenden Sie den LOOP-Befehl mit dem Zusatz ASSIGNING um bei jedem Schleifendurchlauf der jeweiligen Zeile ein Feldsymbol zuzuweisen.
TYPES: BEGIN OF zeile_typ, thandy TYPE /bi0/oimaterial, tpreis TYPE /bi0/oiamount, END OF zeile_typ. DATA: lt_itab TYPE TABLE OF zeile_typ. FIELD-SYMBOLS: <ls_itab> TYPE zeile_typ. SELECT * FROM zsmartphones2 INTO CORRESPONDING FIELDS OF TABLE lt_itab. LOOP AT lt_itab ASSIGNING <ls_itab>. <ls_itab>-tpreis = 1. MODIFY lt_itab FROM <ls_itab>. ENDLOOP.
Der Befehl MODIFY ändert nur der Inhalt einer bestehenden Zeile der internen Tabelle. Es wird keine neue Zeile angelegt. Wenn die MODIFY-Anweisung in der LOOP-Schleife steht, wird immer die aktuelle Zeile geändert. Allerdings darf bei Tabellen mit einem eindeutigen Schlüssel der Schlüssel nicht geändert werden.
Steht die Anweisung außerhalb der Schleife, müssen Sie die zu ändernde Zeile über den Index angeben.
DESCRIBE TABLE
Mit der Anweisung DESCRIBE TABLE können Sie die Anzahl der Rumpfzeilen, den reservierten Speicherplatz und die Tabellenart abfragen. In unserem Beispiel wollen wir die Anzahl der Rumpfzeilen wissen. Diese können Sie über den Zusatz LINES ermitteln.
DESCRIBE TABLE lt_itab LINES lv_zeilen.
Die gefundene Anzahl der Zeilen wird in die Variable lv_zeilen vom Typ Integer geschrieben.
INSERT
Die ermittelte Anzahl von Rumpfzeilen könnten Sie verwenden, wenn Sie in die interne Tabelle eine neue Zeile einfügen wollen. Der Befehl hierfür lautet INSERT.
DESCRIBE TABLE lt_itab LINES lv_zeilen. "Anzahl der Zeilen bestimmen *Neue Zeile ls_itab-thandy = '000000000000000005'. ls_itab-tpreis = '500.00'. INSERT ls_itab INTO lt_itab INDEX lv_zeilen.
Im Gegensatz zu der Anweisung APPEND, welche die Zeilen immer am Ende des Tabellenrumpfes anhängt, können Sie mit der INSERT-Anweisung Zeilen an beliebiger Stelle einfügen. Grundsätzlich wird die neue Zeile immer vor der Position eingefügt, die Sie mit dem Zusatz INDEX angegeben haben. Wenn Sie zum Beispiel INDEX 4 angeben, wird die neue Zeile vor der alten Zeile 4 eingefügt. In unserem Beispiel sieht das Ergebnis wie folgt aus.
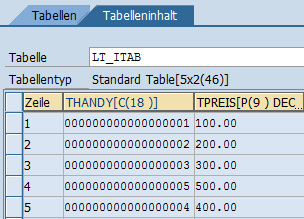
Neue Zeile eingefügt
Wenn Sie den Inhalt der Variable lv_zeilen um 1 erhöhen, wird die neue Zeile ganz unten angehängt. In diesem Fall ist die Wirkung der Anweisungen INSERT und APPEND identisch.
DESCRIBE TABLE lt_itab LINES lv_zeilen. lv_zeilen = lv_zeilen + 1. ls_itab-thandy = '000000000000000005'. ls_itab-tpreis = '500.00'. INSERT ls_itab INTO lt_itab INDEX lv_zeilen.
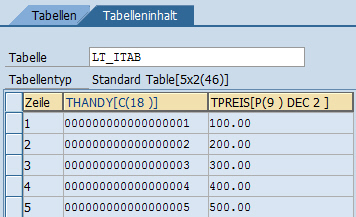
Neue Zeile wird angehängt
READ
Standardtabellen können Sie über einen Index oder einen Schlüssel lesen. Um die erste Zeile der Tabelle zu lesen, verwenden Sie die folgende Anweisung.
READ TABLE lt_itab INDEX 1 INTO ls_itab.
Statt der 1 können Sie auch eine Variable verwenden, wie in den obigen Beispielen. Falls Sie den Index nicht ermitteln können, können Sie auch über Schlüsselfelder auf die Tabelle zugreifen.
Interne Tabellen besitzen immer einen nicht eindeutigen NON-UNIQUE Schlüssel. Daher müssen Sie sich überlegen, durch welche Schlüsselfelder Sie eine Zeile möglichst eindeutig bestimmen können. Beachten Sie, dass in Standardtabellen die Zeilen mehrfach vorkommen können. Die READ-Anweisung zieht aber (ausgehend vom Tabellenanfang) nur den ersten passenden Satz, ohne weiter zu schauen ob es möglicherweise noch weitere Treffer gibt.
Die Syntax sieht wie folgt aus.
READ TABLE lt_itab INTO ls_itab WITH KEY tpreis = '100.00'.
Dabei wird aus den Rumpfzeilen der internen Tabelle lt_itab die erste passende Zeile in die Workarea ls_itab, bei der das Feld tpreis den Inhalt 100 hat. Es könnten in der Tabelle jedoch mehrere Zeilen mit diesem Feldinhalt stehen. So könnte es mehrere Smartphonemodelle geben, die 100 Euro kosten. Die 100 könnten auch in verschiedenen Währungen in der Tabelle abgelegt werden. Die READ-Anweisung prüft dies jedoch nicht mehr. Sie schnappt sich den erstbesten Treffer.
Wenn Sie eine Standardtabelle über die Anweisung SORT sortieren, können Sie mit dem Zusatz BINARY SEARCH eine binäre Suche durchführen.
DELETE
Auch beim Löschen einer Zeile können Sie auf den Index zugreifen. Wenn Sie zum Beispiel die erste Zeile löschen wollen, verwenden Sie den folgenden Befehl.
DELETE lt_itab INDEX 1.
Alternativ können Sie die relevante Zeile über den Inhalt des Arbeitsbereichs identifizieren. Wie bei der READ-Anweisung sucht DELETE, vom Tabellenanfang aus, der ersten passenden Satz in den Rumpfzeilen und löscht auch nur diesen. Verwenden Sie dabei den Zusatz TABLE.
ls_itab-thandy = '000000000000000001'. ls_itab-tpreis = '100.00'. DELETE TABLE lt_itab FROM ls_itab.
DELETE ADJACENT DUPLICATES
Die Anweisung DELETE ADJACENT DUPLICATES bietet die Möglichkeit redundante Zeilen zu löschen. Zuvor müssen Sie die interne Tabelle entsprechend sortieren. Anschließend werden die redundanten Zeilen bis auf eine gelöscht.
SORT lt_itab BY thandy. DELETE ADJACENT DUPLICATES FROM lt_itab.
Inhalte von internen Tabellen löschen
Die Inhalte der Workarea und der internen Tabelle bleiben so lange erhalten, bis sie überschrieben werden. Das kann unter Umständen zu unsinnigen Ergebnissen führen, siehe Beispiel unten.
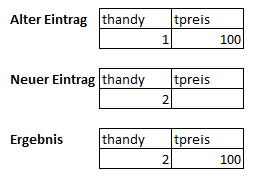
Unsinnige Ergebnisse
Je nach Aufgabenstellung kann es daher erforderlich sein, die Workarea und den Tabellenrumpf zu leeren. Hierzu gibt es verschiedene Möglichkeiten.
CLEAR
Interne Tabellen können durch die Anweisung CLEAR initialisiert (gelöscht) werden. Mit dem folgenden Befehl löschen sie alle Rumpfzeilen.
CLEAR lt_itab.
Mit demselben Befehl können Sie auch die Workarea initialisieren.
CLEAR ls_itab.
Sie können die Anweisung natürlich auch als Kettensatz formulieren.
CLEAR: lt_itab, ls_itab.
FREE
Alternativ können Sie auch den Befehl FREE verwenden.
FREE lt_itab, ls_itab.
Während bei CLEAR der zugewiesene Speicherplatz reserviert bleibt, gibt FREE den gesamten durch die Tabelle beanspruchten Speicher frei. Zwar kann die interne Tabelle jederzeit erneut angesprochen werden, allerdings muss das System zuerst den Speicherplatz wieder reservieren. Das kann Performance kosten.
Quellen:
Karl-Heinz Kühnhauser, Thorsten Franz (2011): Discover ABAP, 3. Auflage, Bonn
Dirk Herzog (2012): ABAP-Programmierung für SAP NetWeaver BW – Kundeneigene Erweiterungen, 3. Auflage, Bonn
Diese ABAP Tricks machen Ihr Leben leichter!
- In meinem Newsletter gebe ich eine Menge Tipps und Kniffe rund um ABAP.
- Die Mini-Tutorials unterstützen Sie dabei, Software in ABAP effizienter zu entwickeln.
- Praktische Anleitungen ermöglichen Ihnen schnelle Erfolge bei der Optimierung Ihrer Arbeit.
- Bei der Anmeldung zu meinem Newsletter erhalten Sie das Buch „ABAP Tipps und Tricks“ als Willkommensgeschenk.

SAP Hilfe – Interne Tabellen
SAP Hilfe – Binäre Suche bei Standard-Tabellen
SAP Hilfe – Interne Tabellen bearbeiten
SAP Hilfe – ABAP-Systemfelder
Falls Ihnen dieser Beitrag weitergeholfen hat, wäre es eine sehr nette Anerkennung meiner Arbeit wenn Sie z.B. Ihre Bücher über Amazon bestellen würden. Wenn Sie ein Produkt kaufen, erhalte ich dafür eine Provision. Für Sie ändert sich am Preis des Produktes gar nichts. Ich möchte mich an dieser Stelle jetzt schon für Ihre Unterstützung bedanken.




Schöner Artikel. Im ersten Satz („In diesem Artikel stelle interne Tabellen vor.“) fehlt ein „ich“.
Hallo Stefan, vielen Dank! Fixed.