SQL Spickzettel

Wenn Sie alle paar Jahre SQL schreiben, vergessen Sie leicht die Syntax. In diesem Fall können Sie diesen Spickzettel nutzen. Die folgenden Beispiele basieren auf einer MySQL Datenbank.
Inhaltsverzeichnis
- Nützliche Links
- CRUD
- Kategorien
- Optimizing SQL Queries
- Kommentare
- Escape Character
- Vergleichsoperatoren
- Datenbank anlegen
- Datentypen
- Tabelle anlegen –
CREATE TABLE - Tabelle kopieren –
CREATE TABLE x LIKE y; - Tabelle löschen –
DROP TABLE - Tabelle beschreiben –
DESCRIBE TABLE - Spalten der Tabelle anzeigen –
DESCRIBE - Spalte hinzufügen –
ALTER TABLE ... ADD - Spalte löschen –
ALTER TABLE ... DROP COLUMN - Daten einfügen –
INSERT INTO - Daten kopieren–
INSERT INTO... SELECT - Daten lesen / aufrufen –
SELECT - Konvertierung –
CAST - Daten löschen –
DELETE - Daten ändern –
UPDATE - SQL Funktionen –
COUNT,AVG,SUM - Aggregation –
GROUP BY HAVING–WHEREfür Aggregationen- Wildcards
UNIONJOIN- Nested Queries
Nützliche Links
- PopSQL Editor – Output: Export > Copy TSV
- MySQL Reference Manual
- w3schools SQL
- MySQL Connector/Python Developer Guide
- MySQL Connector/Python Coding Examples
- SAP HANA Python Client
- SQL – Database Programming Tutorial von Giraffe Academy
CRUD
Create Read Update Delete
Kategorien
- DDL – Data Definition Language –
CREATE,DROP,ALTER, etc - DQL – Data Query Language –
SELECT - DML – Data Manipulation Language –
INSERT,UPDATE,DELETE, etc - DCL – Data Control Language –
GRANT,REVOKE - TCL – Transaction Control Language –
COMMIT,SAVEPOINT,ROLLBACK
Optimizing SQL Queries
Secret To Optimizing SQL Queries – Understand The SQL Execution Order by ByteByteGo
SELECT customer_id, COUNT(order_id) as total_orders,
SUM(order_amount) as total_spent
FROM customers
JOIN orders
ON customers.id = orders.customer_id
WHERE ORDER_DATE >= '2023-01-01'
AND customer_id
AND total_spent >= 1000
ORDER BY total_spent DESC
LIMIT 10;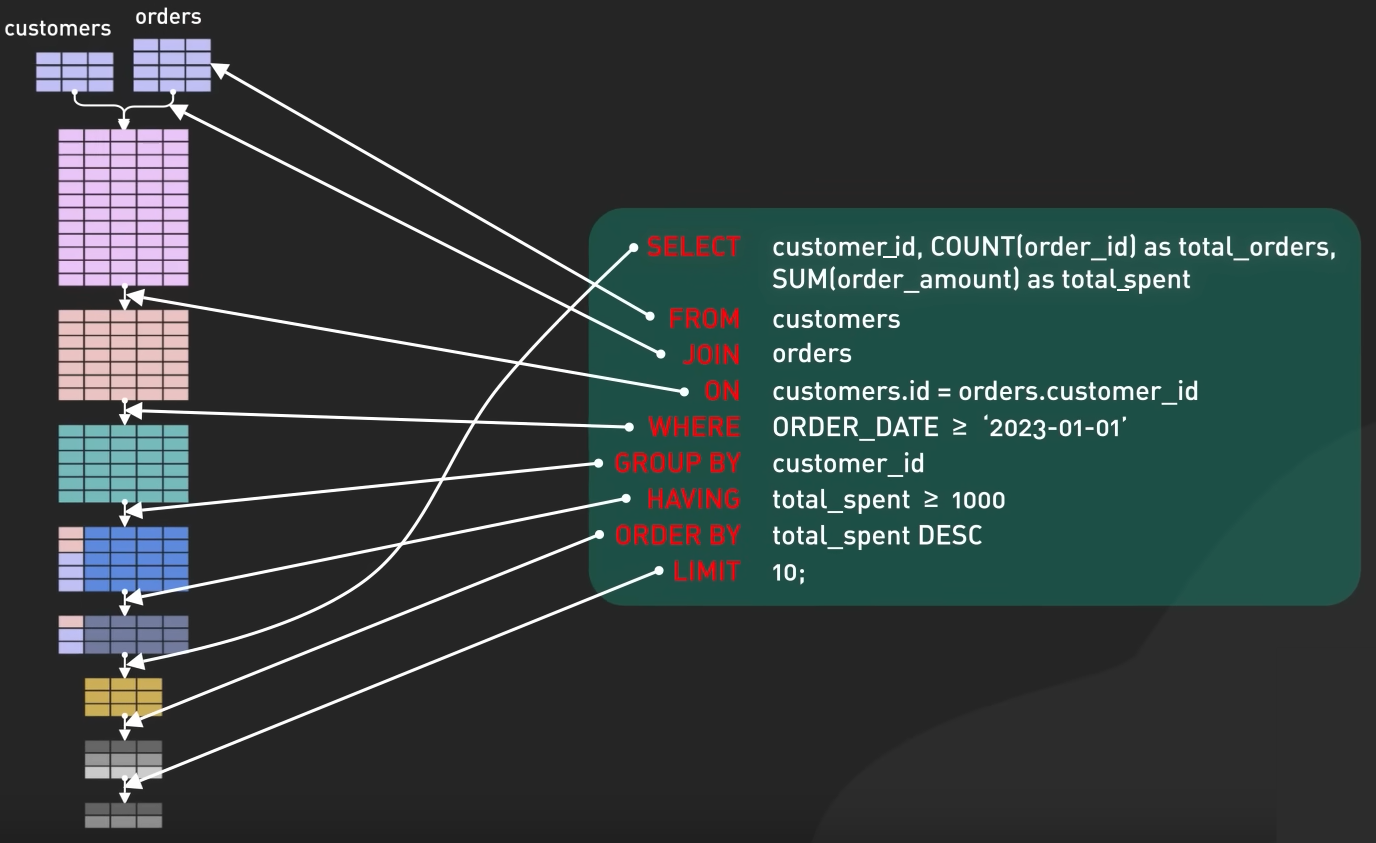
Kommentare
-- Inline comment
-- Select all:
SELECT * FROM student; SELECT * FROM student -- Select all:/* Block comment
Select all the columns
of all the records
in the Customers table:*/
SELECT * FROM student;SELECT student_id, /*City,*/ major FROM student; -- Ignore part of the statementEscape Character
Backslash \ als Escape
MySQL Reference – String Literals
SELECT 'hello', '"hello"', '""hello""', 'hel''lo', '\'hello';
--Ausgabe:
+-------+---------+-----------+--------+--------+
| hello | "hello" | ""hello"" | hel'lo | 'hello |
+-------+---------+-----------+--------+--------+Ausgabe

SELECT "hello", "'hello'", "''hello''", "hel""lo", "\"hello";
--Ausgabe:
+-------+---------+-----------+--------+--------+
| hello | 'hello' | ''hello'' | hel"lo | "hello |
+-------+---------+-----------+--------+--------+Backslash \ und das Anführungszeichen, das zum Anführen der Zeichenkette verwendet wird, müssen maskiert werden.
SELECT "\\hello";
--gibt \hello ausBacktick ` als identifier quote in MySQL, in anderen Brackets [].
SELECT * FROM `select` WHERE `select`.id > 100;
SELECT * FROM [select] WHERE [select].id > 100;Datenbank anlegen
CREATE DATABASE newdb;Datentypen
Siehe auch w3schools
INT -- Whole numbers
DECIMAL(10,2) -- Decimal numbers, exact value
VARCHAR(100) -- String
DATE -- YYY-MM-DD
TIMESTAMP - YYYY-MM-DD HH:MM:SSTabelle anlegen
CREATE TABLE student (
student_id INT PRIMARY KEY,
name VARCHAR(20),
major VARCHAR(20)
);Mehrere Schlüssel
CREATE TABLE MYTABLE_001 (
"Version" NVARCHAR(300) NOT NULL,
"Date" NVARCHAR(6) NOT NULL,
BUKRS NVARCHAR(256) NOT NULL,
PRCTR NVARCHAR(256) NOT NULL,
ACCNT NVARCHAR(256) NOT NULL,
"Amount_LC" DECIMAL(31,2),
PRIMARY KEY ("Version", "Date", BUKRS, PRCTR, ACCNT)
);Initiale Werte nicht erlauben – NOT NULL
Nur ein Wert pro Tabelle erlauben – UNIQUE
CREATE TABLE student (
student_id INT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
major VARCHAR(20)
);Standardwert auf # (nicht zugeordnet) setzen
CREATE TABLE student (
student_id INT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
major VARCHAR(20) DEFAULT '#'
);Wenn explizit NULL gesetzt wird, nicht erlaubt. Wwenn nichts eingegeben wird, wird es auf Standardwert # gesetzt.
CREATE TABLE student (
student_id INT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
major VARCHAR(20) NOT NULL DEFAULT '#'
);Key automatisch erhöhen
CREATE TABLE student (
student_id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
major VARCHAR(20)
);
-- dann brauche ich die student_id nicht zu übergeben
INSERT INTO student (name, major)
VALUES
('Jack', 'Biology'),
('Kate', 'Sociology'),
('Claire', 'English'),
('Jack', 'Biology'),
('Mike', 'Computer Science');Mit foreign key
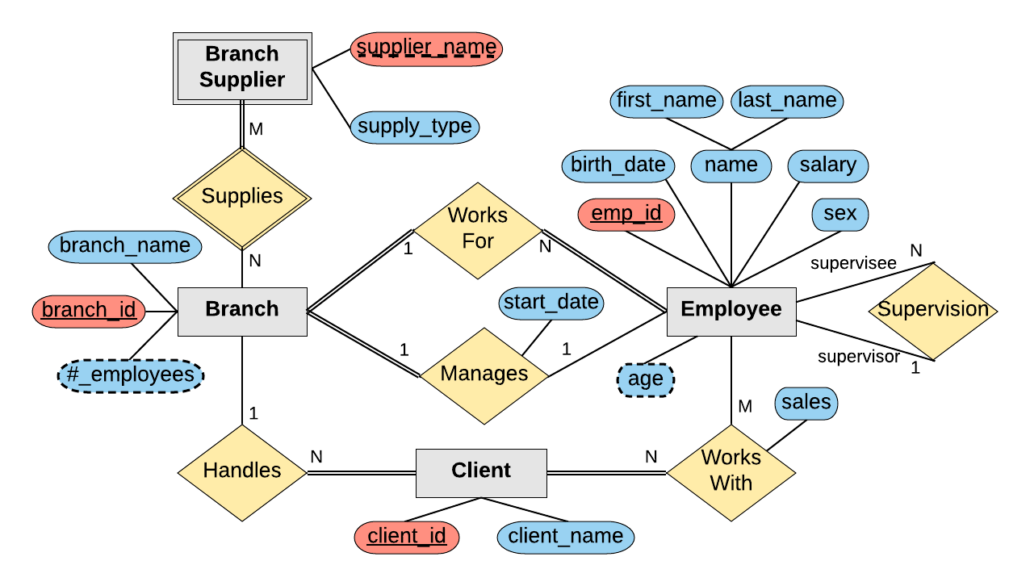

CREATE TABLE employee (
emp_id INT PRIMARY KEY,
first_name VARCHAR(40),
last_name VARCHAR(40),
birth_day DATE,
sex VARCHAR(1),
salary INT,
super_id INT,
branch_id INT
);
CREATE TABLE branch (
branch_id INT PRIMARY KEY,
branch_name VARCHAR(40),
mgr_id INT,
mgr_start_date DATE,
FOREIGN KEY(mgr_id) REFERENCES employee(emp_id) ON DELETE SET NULL
);
ALTER TABLE employee
ADD FOREIGN KEY(branch_id)
REFERENCES branch(branch_id)
ON DELETE SET NULL;
ALTER TABLE employee
ADD FOREIGN KEY(super_id)
REFERENCES employee(emp_id)
ON DELETE SET NULL;
DESCRIBE employee;
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40),
branch_id INT,
FOREIGN KEY(branch_id) REFERENCES branch(branch_id) ON DELETE SET NULL
);
CREATE TABLE works_with (
emp_id INT,
client_id INT,
total_sales INT,
PRIMARY KEY(emp_id, client_id),
FOREIGN KEY(emp_id) REFERENCES employee(emp_id) ON DELETE CASCADE,
FOREIGN KEY(client_id) REFERENCES client(client_id) ON DELETE CASCADE
);
CREATE TABLE branch_supplier (
branch_id INT,
supplier_name VARCHAR(40),
supply_type VARCHAR(40),
PRIMARY KEY(branch_id, supplier_name),
FOREIGN KEY(branch_id) REFERENCES branch(branch_id) ON DELETE CASCADE
);Tabelle kopieren
Tabelle anhand einer anderen Tabelle anlegen
CREATE TABLE student_backup LIKE student;Tabelle löschen
DROP TABLE student;Der Befehl TRUNCATE TABLE löscht die Daten innerhalb einer Tabelle, aber nicht die Tabelle selbst.
TRUNCATE TABLE student; Tabelle beschreiben
DESCRIBE TABLE student;Spalten der Tabelle anzeigen
DESCRIBE student; -- ohne TABLE
-- oder
SHOW COLUMNS FROM student;Spalte hinzufügen
ALTER TABLE student ADD gpa DECIMAL(3,2);Neue Spalte als Schlüssel einfügen
--add new column
ALTER TABLE student
ADD COLUMN calendaryear YEAR; -- data type YEAR
-- Drop the existing primary key constraint
ALTER TABLE student
DROP PRIMARY KEY;
-- Fill column with value
UPDATE student SET calendaryear = 2024;
-- Add a composite primary key
ALTER TABLE student
ADD PRIMARY KEY (student_id, calendaryear);Spalte löschen
ALTER TABLE student DROP COLUMN gpa;Daten einfügen
In der Reihenfolge der definierten Spalten. Strings mit ‚ ‚ oder “ „.
INSERT INTO student VALUES(1, 'Jack', 'Biology');
INSERT INTO student VALUES(1, "Jack", "Biology");
INSERT INTO student VALUES(1, "Jack", 'Biology');Mehrere Werte einfügen
INSERT INTO student (student_id, name, major)
VALUES
(1, 'Jack', 'Biology'),
(2, 'Kate', 'Sociology'),
(3, 'Claire', 'English'),
(4, 'Jack', 'Biology'),
(5, 'Mike', 'Computer Science');INSERT INTO student
VALUES
(1, 'Jack', 'Biology'),
(2, 'Kate', 'Sociology'),
(3, 'Claire', 'English'),
(4, 'Jack', 'Biology'),
(5, 'Mike', 'Computer Science');Daten in bestimmte Spalten einfügen. Hier ohne major Spalte.
INSERT INTO student(student_id, name) VALUES(3, 'Claire');INSERT INTO student VALUES(3, 'Claire', NULL);Mit foreign key
-- Corporate
INSERT INTO employee VALUES(100, 'David', 'Wallace', '1967-11-17', 'M', 250000, NULL, NULL);
INSERT INTO branch VALUES(1, 'Corporate', 100, '2006-02-09');
UPDATE employee
SET branch_id = 1
WHERE emp_id = 100;
INSERT INTO employee VALUES(101, 'Jan', 'Levinson', '1961-05-11', 'F', 110000, 100, 1);
-- Scranton
INSERT INTO employee VALUES(102, 'Michael', 'Scott', '1964-03-15', 'M', 75000, 100, NULL);
INSERT INTO branch VALUES(2, 'Scranton', 102, '1992-04-06');
UPDATE employee
SET branch_id = 2
WHERE emp_id = 102;
INSERT INTO employee VALUES(103, 'Angela', 'Martin', '1971-06-25', 'F', 63000, 102, 2);
INSERT INTO employee VALUES(104, 'Kelly', 'Kapoor', '1980-02-05', 'F', 55000, 102, 2);
INSERT INTO employee VALUES(105, 'Stanley', 'Hudson', '1958-02-19', 'M', 69000, 102, 2);
-- Stamford
INSERT INTO employee VALUES(106, 'Josh', 'Porter', '1969-09-05', 'M', 78000, 100, NULL);
INSERT INTO branch VALUES(3, 'Stamford', 106, '1998-02-13');
UPDATE employee
SET branch_id = 3
WHERE emp_id = 106;
INSERT INTO employee VALUES(107, 'Andy', 'Bernard', '1973-07-22', 'M', 65000, 106, 3);
INSERT INTO employee VALUES(108, 'Jim', 'Halpert', '1978-10-01', 'M', 71000, 106, 3);
-- BRANCH SUPPLIER
INSERT INTO branch_supplier VALUES(2, 'Hammer Mill', 'Paper');
INSERT INTO branch_supplier VALUES(2, 'Uni-ball', 'Writing Utensils');
INSERT INTO branch_supplier VALUES(3, 'Patriot Paper', 'Paper');
INSERT INTO branch_supplier VALUES(2, 'J.T. Forms & Labels', 'Custom Forms');
INSERT INTO branch_supplier VALUES(3, 'Uni-ball', 'Writing Utensils');
INSERT INTO branch_supplier VALUES(3, 'Hammer Mill', 'Paper');
INSERT INTO branch_supplier VALUES(3, 'Stamford Labels', 'Custom Forms');
-- CLIENT
INSERT INTO client VALUES(400, 'Dunmore Highschool', 2);
INSERT INTO client VALUES(401, 'Lackawana Country', 2);
INSERT INTO client VALUES(402, 'FedEx', 3);
INSERT INTO client VALUES(403, 'John Daly Law, LLC', 3);
INSERT INTO client VALUES(404, 'Scranton Whitepages', 2);
INSERT INTO client VALUES(405, 'Times Newspaper', 3);
INSERT INTO client VALUES(406, 'FedEx', 2);
-- WORKS_WITH
INSERT INTO works_with VALUES(105, 400, 55000);
INSERT INTO works_with VALUES(102, 401, 267000);
INSERT INTO works_with VALUES(108, 402, 22500);
INSERT INTO works_with VALUES(107, 403, 5000);
INSERT INTO works_with VALUES(108, 403, 12000);
INSERT INTO works_with VALUES(105, 404, 33000);
INSERT INTO works_with VALUES(107, 405, 26000);
INSERT INTO works_with VALUES(102, 406, 15000);
INSERT INTO works_with VALUES(105, 406, 130000);Daten kopieren
Daten innerhalb einer Tabelle kopieren
INSERT INTO student (student_id, name, major, calendaryear)
SELECT student_id, name, major, "2025"
FROM student
WHERE calendaryear = "2024";Die Anweisung SELECT INTO kopiert Daten aus einer Tabelle in eine neue Tabelle.
-- Creating students_backup table with the same structure
CREATE TABLE student_backup LIKE student;
INSERT INTO student_backup
SELECT *
FROM student;
--WHERE <condition>; INSERT INTO student_backup (student_id, name, major, calendaryear)
SELECT student_id, name, major, "2025"
FROM student
WHERE calendaryear = "2024";Nur ausgewählte Spalten kopieren
INSERT INTO student_backup (student_id, name)
SELECT student_id, name
FROM student
WHERE major = 'Biology'; Daten lesen / aufrufen
Alle Einträge selektieren. Liest alle Spalten. Performance beachten! Im Produktivsystem immer mit WHERE und/oder LIMIT arbeiten.
SELECT * FROM student;Ausgewählte Spalten lesen
SELECT name FROM student;SELECT name, major
FROM student;SELECT student.name, student.major
FROM student;Namen der ausgegebenen Spalte ändern. SELECT AS
SELECT
first_name AS forename,
last_name AS surname
FROM employee;Sortieren, standardmäßig aufsteigend
SELECT student.name, student.major
FROM student
ORDER BY name;Absteigend sortieren
SELECT student.name, student.major
FROM student
ORDER BY name DESC;SELECT *
FROM employee
ORDER BY salary;Sortierattribut muss nicht unbedingt in der Abfrage sein
SELECT student.name, student.major
FROM student
ORDER BY student_id DESC;Nach mehreren Spalten sortieren. Zuerst nach major, danach nach student_id. Wenn sie dasselbe Fach (major) haben, werden sie innerhalb des Fachs nach ID sortiert.
SELECT *
FROM student
ORDER BY major, student_id DESC;Zuerst nach Geschlecht, dann nach Namen sortieren.
SELECT *
FROM employee
ORDER BY sex, first_name, last_name;Anzahl der Ergebnisse limitieren. Die ersten zwei.
SELECT *
FROM student
LIMIT 2;Die unteren zwei lesen
SELECT *
FROM student
ORDER BY student_id DESC
LIMIT 2;Filtern mit WHERE
SELECT *
FROM student
WHERE major = 'Biology'; Nur ausgewählte Spalten lesen
SELECT name, major
FROM student
WHERE major = 'Biology'; SELECT name, major
FROM student
WHERE major = 'Biology' OR major = 'Chemistry'; SELECT name, major
FROM student
WHERE major = 'Biology' OR name = 'Kate'; SELECT *
FROM student
WHERE student_id <= 3; SELECT *
FROM student
WHERE student_id <= 3 AND name <> 'Jack'; Nur Werte in der angegebenen Liste selektieren. Nur wenn der Name Claire, Kate oder Mike ist.
SELECT *
FROM student
WHERE name IN ('Claire', 'Kate', 'Mike');SELECT *
FROM student
WHERE major IN ('Biology', 'Chemistry') AND student_id > 2;Die Anweisung SELECT DISTINCT wird verwendet, um nur eindeutige (unterschiedliche) Werte zurückzugeben.
SELECT DISTINCT sex
FROM employee;
-- Gibt zwei Zeilen: M und F ausVergleichsoperatoren
<>not equals- = equals
>greater than>less than>=greater than or equal<=less than or equal
Daten konvertieren
Die Funktion CAST() konvertiert einen Wert in den angegebenen Datentyp. Die Funktion CAST() ist nur dann erfolgreich, wenn der Zieldatentyp den ursprünglichen Wert aufnehmen kann. Die Umwandlung einer Ganzzahl in einen Text ist möglich, da die Zeichentypen Zahlen enthalten können. Die Umwandlung von Text mit Buchstaben des Alphabets in eine Zahl ist nicht möglich.
-- postgres db
CREATE TABLE number_data_types (
numeric_column numeric(20,5),
real_column real,
double_column double precision
);
INSERT INTO number_data_types
VALUES
(.7, .7, .7),
(2.13579, 2.13579, 2.13579),
(2.1357987654, 2.1357987654, 2.1357987654);
SELECT * FROM number_data_types;Ausgabe:
numeric_column real_column double_column
0.70000 0.7 0.7
2.13579 2.13579 2.13579
2.13580 2.1357987 2.1357987654Konvertierung mit CAST().
SELECT numeric_column,
CAST(numeric_column AS integer),
CAST(numeric_column AS text)
FROM number_data_types;Ausgabe:
numeric_column numeric_column_2 numeric_column_3
0.70000 1 0.70000
2.13579 2 2.13579
2.13580 2 2.13580Daten löschen
Alle Daten in der Tabelle löschen
DELETE FROM student;Daten selektiv löschen
DELETE FROM student WHERE major='Biology';DELETE FROM student
WHERE name = 'Tom' and major = 'undecided';Der Befehl TRUNCATE TABLE löscht die Daten innerhalb einer Tabelle, aber nicht die Tabelle selbst.
TRUNCATE TABLE student; Daten ändern / Update
„Biology“ mit „Bio“ ersetzen
UPDATE student
SET major = 'Bio'
WHERE major = 'Biology';Mit OR
UPDATE student
SET major = 'Biochemistry'
WHERE major = 'Bio' OR major = 'Chemistry';Inhalt von zwei Spalten anpassen
UPDATE student
SET name='Tom', major = 'undecided'
WHERE student_id = 1;Spalteninhalt von allen Zeilen ändern
UPDATE student
SET major = 'undecided';SQL Funktionen
SAP Datasphere SQL Functions Reference
Die Funktion COUNT() gibt die Anzahl der von einer Select-Abfrage zurückgegebenen Datensätze zurück. Mitarbeiter zählen.
SELECT COUNT(emp_id)
FROM employee;
-- gibt 9 zurückAnzahl der weiblichen Beschäftigten, die nach 1970 geboren sind, ermitteln.
SELECT COUNT(emp_id)
FROM employee
WHERE sex='F' AND birth_day > '1970-01-01';Durchschnitt der Gehälter aller Mitarbeiter ermitteln.
SELECT AVG(salary)
FROM employee;SELECT AVG(salary)
FROM employee
WHERE sex = 'M';Summe der Gehälter
SELECT SUM(salary)
FROM employee;Aggregation
Anzahl der männlichen und weiblichen Mitarbeiter ermitteln.
SELECT COUNT(sex), sex
FROM employee
GROUP BY sex;Gesamtumsatz jedes Verkäufers ermitteln
SELECT SUM(total_sales), emp_id
FROM works_with
GROUP BY emp_id;Wieviel gibt der jeweilige Kunde aus?
SELECT SUM(total_sales), client_id
FROM works_with
GROUP BY client_id
ORDER BY SUM(total_sales);HAVING – WHERE für Aggregationen
Die HAVING-Klausel wurde zu SQL hinzugefügt, weil das Schlüsselwort WHERE nicht mit Aggregatfunktionen verwendet werden kann.
SELECT emp_id, SUM(total_sales) AS sales
FROM works_with
GROUP BY emp_id
HAVING sales >= 200000
ORDER BY sales DESC;Wildcards
-- % = any # of characters
-- _ = one character
-- Find any clients who are an LLC
SELECT *
FROM client
WHERE client_name LIKE '%LLC';
--If the client name is like this pattern - any number of characters and LLC at the end-- Find any branch suplliers who are in the label business
SELECT *
FROM branch_supplier
WHERE supplier_name LIKE '%Label%';
-- If Label is anywhere in the name-- Find any employee born in October.
SELECT *
FROM employee
WHERE birth_day LIKE '____-10%';
-- Match with 4 characters (4x _), - and 10. Afterwards any character.-- Find any employee born in February.
SELECT *
FROM employee
WHERE birth_day LIKE '____-02%';
-- Match with 4 characters (4x _), - and 02. Afterwards any character.Union
Kombiniert die Ergebnismenge von zwei oder mehr SELECT-Anweisungen. Datentypen und Anzahl der Spalten müssen übereinstimmen.
-- Find a list of employee and branch names
SELECT first_name
FROM employee;
SELECT branch_name
FROM branch;
-- Combine those together
SELECT first_name
FROM employee
UNION
SELECT branch_name
FROM branch;
-- Three tables
SELECT first_name
FROM employee
UNION
SELECT branch_name
FROM branch
UNION
SELECT client_name
FROM client;
Spaltenüberschrift anpassen – AS Names
SELECT first_name AS Names
FROM employee
UNION
SELECT branch_name
FROM branch
UNION
SELECT client_name
FROM client;Zwei Spalten selektieren
-- Find a list of all clients and branch suppliers' names
SELECT client_name, branch_id
FROM client
UNION
SELECT supplier_name, branch_id
FROM branch_supplier;
-- Identifies the source table for more readability
SELECT client_name, client.branch_id
FROM client
UNION
SELECT supplier_name, branch_supplier.branch_id
FROM branch_supplier;Verschiedene Spalten
-- Display all money spent or earned by the company
SELECT salary AS cash_flow
FROM employee
UNION
SELECT total_sales
FROM works_with;Temporäre Spalte für die Laufzeit. Beachten Sie das „AS Type“ oben – es ist ein Alias. SQL-Aliase werden verwendet, um einer Tabelle oder einer Spalte einen temporären Namen zu geben. Ein Alias existiert nur für die Dauer der Abfrage. Hier haben wir also eine temporäre Spalte mit dem Namen „Typ“ erstellt, die auflistet, ob die Kontaktperson ein „Kunde“ oder ein „Lieferant“ ist. „Kunden“ kommen aus der Kundentabelle, „Lieferanten“ kommen aus der Lieferantentabelle.
SELECT 'Customer' AS Type, ContactName, City, Country
FROM Customers
UNION
SELECT 'Supplier', ContactName, City, Country
FROM Suppliers;Joins
Kombiniert Inhalte von verschiedenen Tabellen, basiered auf einer gemeinsamen Spalte. ABAP Beispiel.
(INNER) JOIN: Gibt Datensätze zurück, deren Werte in beiden Tabellen übereinstimmen.LEFT (OUTER) JOIN: Gibt alle Datensätze aus der linken Tabelle und die übereinstimmenden Datensätze aus der rechten Tabelle zurückRIGHT (OUTER) JOIN: Gibt alle Datensätze aus der rechten Tabelle und die übereinstimmenden Datensätze aus der linken Tabelle zurückFULL (OUTER) JOIN: Gibt alle Datensätze zurück, wenn es entweder in der linken oder der rechten Tabelle eine Übereinstimmung gibt. (in MySQL nicht möglich)

-- Vorbereitung
INSERT INTO branch VALUES(4, 'Buffalo', NULL, NULL);
SELECT * FROM branch;
SELECT * FROM employee;
-- Find all branches and the names of their managers
SELECT *
FROM employee
JOIN branch
on employee.emp_id = branch.mgr_id;
-- Find all branches and the names of their managers
SELECT employee.emp_id, employee.first_name, branch.branch_name
FROM employee
JOIN branch -- join the employee table and branch table together
on employee.emp_id = branch.mgr_id; -- using content of emp_id and mgr_id column
-- combine all rows as long as their mgr_id is equal to emp_id
-- mgr_id in branch und emp_id in employee speichern beide die ID des Angestellten
-- output:
emp_id first_name branch_name
100 David Corporate
102 Michael Scranton
106 Josh Stamfordemp_id und mgr_id stimmen überein:
SELECT employee.emp_id, branch.mgr_id, employee.first_name, branch.branch_name
FROM employee
JOIN branch
on employee.emp_id = branch.mgr_id;
-- output:
emp_id mgr_id first_name branch_name
100 100 David Corporate
102 102 Michael Scranton
106 106 Josh StamfordLEFT JOIN gibt alle Angestellten aus, auch wenn diese keine Manager sind. Gibt für Manager die entsprechende Branche aus, ansonsten NULL.
SELECT employee.emp_id, employee.first_name, branch.branch_name
FROM employee
LEFT JOIN branch
on employee.emp_id = branch.mgr_id;
-- output:
emp_id first_name branch_name
100 David Corporate
101 Jan ""
102 Michael Scranton
103 Angela ""
104 Kelly ""
105 Stanley ""
106 Josh Stamford
107 Andy ""
108 Jim ""RIGHT JOIN gibt alle Branchen aus, auch wenn diese keinem Manager zugeordnet sind.
SELECT employee.emp_id, employee.first_name, branch.branch_name
FROM employee
RIGHT JOIN branch
on employee.emp_id = branch.mgr_id;
-- output:
emp_id first_name branch_name
100 David Corporate
102 Michael Scranton
106 Josh Stamford
"" "" BuffaloNested Queries
Mehrere SELECT Statements verschachtelt.
-- Find names of all employess who
-- sold over 30.000 to a single client
SELECT works_with.emp_id
FROM works_with
WHERE works_with.total_sales > 30000;
-- output:
emp_id
102
105
105
105Gibt den Vor- und Nachnamen der Angestellten aus, die in der ersten Query auftauchten.
SELECT employee.first_name, employee.last_name
FROM employee
WHERE employee.emp_id IN (
SELECT works_with.emp_id
FROM works_with
WHERE works_with.total_sales > 30000;
)
--output:
first_name last_name
Michael Scott
Stanley HudsonFinde alle Kunden, die von der Filiale, die Michael Scott leitet, betreut werden.
SELECT branch.branch_id
FROM branch
WHERE branch.mgr_id = 102;
-- output: branch_id 2
-- Find all clients who are handeld by the branch that Michael Scott manages
-- Assume you know Michael's ID
SELECT client.client_name
FROM client
WHERE client.branch_id = (
SELECT branch.branch_id
FROM branch
WHERE branch.mgr_id = 102
LIMIT 1
);
-- output:
client_name
Dunmore Highschool
Lackawana Country
Scranton Whitepages
FedEx

Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!